Hacking the SEAMs:
Elevating Digital Autonomy and Agency for Humans
Richard S. Whitt[1]*
“Certainty hardens our minds against possibility.”
–Ellen Langer
The time has come to challenge the predominant paradigm of the World Wide Web. We need to replace controlling “SEAMs” with empowering “HAACS.”
Over the past two decades, Web platform ecosystems have been employing the SEAMs paradigm—Surveil users, Extract data, Analyze for insights, and Manipulate for impact. The SEAMs paradigm is embedded as reinforcing feedback cycles in computational systems that mediate, and seek to control, aspects of human experience.
Fronting that SEAMs paradigm are unbalanced multisided platforms (treating patrons as mere users), Institutional AIs (consequential and inscrutable decision engines), and asymmetrical interfaces (one-way device screens, environmental scenes, and bureaucratic unseens). Operating behind all of this “cloudtech,” SEAMs-based feedback cycles continually import reams of personal data, and export concerted attempts to influence users.
While holding accountable these Web platform ecosystems is absolutely necessary work, by itself it does not engender true systems change. The approach suggested here is to challenge, and eventually replace, the underlying SEAMs paradigm itself with a far more human-centric one.
The proposed HAACS paradigm is premised on a different approach—human autonomy and agency, via computational systems. Rather than feed controlling tech systems, the HAACS paradigm supports new ecosystems that empower ordinary human beings. This means building institutions, governance frameworks, and technologies that:
Enhance and promote human autonomy (thought) and agency (action);
Conceptualize personal data as flows of digital lifestreams, managed by individuals and communities as stewards under commons and fiduciary law-based governance;
Introduce trustworthy entities, such as digital fiduciaries, to help manage individual and collective digital interactions;
Create Personal AIs, digital agents that represent the human being vis-à-vis Institutional AIs operated by corporate and governmental interests; and
Craft symmetrical interfaces that allow humans to directly engage with, and challenge, controlling computational systems.
Put more simply, these proposals translate into two compact terms: the human governance formula of D≥A (our digital rights should exceed, or at least equal, our analog rights), and the technology design principle of e2a (edge-to-all), as instantiated in various “edgetech” tools.
While the Age of Data remains in its infancy, time is growing short to confront its many underlying assumptions. The proposed new HAACS paradigm represents one such opportunity. Some real-world proposals in Appendix A would leverage multiple ecosystem-building opportunities simultaneously across technology, market, policy, and social environments.
Prologue and Overview: Founding A New Paradigm of Trust
Abiding in the long shadow of a global pandemic, with its pernicious economic and societal fallout, some of us hold a hard-earned opportunity to pause and consider where exactly we are standing. By all accounts, our many intertwined social systems are not serving most of us very well. Some of these systems are failing spectacularly before our eyes—whether falling prey to black swans,[2] or grey rhinos,[3] or simply the ordinary challenges of everyday life.
The likelier pathways leading us to the horizon are not promising: persistent risks to human health, economic vulnerabilities and disparities, systemic racial injustice, cultural clashes, political divides. And still in the offing, large-scale environmental disaster.
One common denominator seems to be that our fundamental freedoms as human beings—the thoughtful autonomy of our inner selves, and the impactful agency of our outer selves—are in real jeopardy. Too often our predominant social systems negate personal context, ignore mutual relationship, and undermine more inclusive perspectives. They constrain more than they liberate.
Even the coolness factor and convenience of our digital technologies mask subtle forms of (more or less) voluntary subjugation. Today, corporations and governments alike are subjecting each of us to a one-sided mix of online platforms, computational systems, and interfaces operating behind what can be thought of as our “screens, scenes, and unseens.” The purpose of all this impressive yet asymmetric “cloudtech” has become clearer with time. Those entities flourishing in the Web platform ecosystem have been perfecting what could be thought of as the SEAMs paradigm. Under this animating principle, the platforms Surveil people, Extract their personal data, Analyze that data for useful insights, and then circle back to Manipulate those same people in various ways. The end goals of this feedback cycle? Ageless ones of greater power, control, and money.
Holding these Web platforms and their ecosystems more accountable for their practices is a necessary objective, particularly in a post-COVID-19 landscape. Nonetheless, this paper focuses on the complementary, more aspirational goal of building novel ecosystems that elevate, rather than constrict, the autonomy and agency of ordinary human beings vis-à-vis digital technologies.
One source of guidance is Donatella Meadows, the great teacher of complexity theory. Meadows observes that there are many ways to alter existing systems so that they “produce more of what we want and less of that which is undesirable.”[4] She charts out a dozen different kinds of leverage points to intervene in floundering systems.[5] Examples include altering the balancing and reinforcing feedback loops (nos. 7 and 8), modifying information flows (no. 6), and creating new forms of self-organization (no. 4).[6]
However, Meadows notes, the single most effective approach is to directly challenge the existing paradigm—with its “great big unstated assumptions”—propping up a suboptimal system.[7] We can do so in two ways: relentlessly pointing out the anomalies and failures of that prevailing paradigm, while also working with active change agents from within the foundations of a new paradigm. As Meadows puts it, “we change paradigms by building a model of the system, which takes us outside the system and forces us to see it whole.”[8]
In light of our current shared societal crises, we can rethink and reshape how digital technologies can be designed to promote and even enhance our individual and collective humanity. As this paper explores, stakeholders have windows of opportunity to support a new Web paradigm: namely, human autonomy and agency via computational systems, or “HAACS.” This new paradigm seeks not just to reduce the harms to Web users emanating from the predominant Web platform ecosystems, but to actively promote the best interests of users as actual human beings.
There are two proposed ways of encapsulating the HAACS paradigm as more precise formulas to guide real action. For institutional governance, D≥A stands for the proposition that our rights as human beings in the digital world should exceed, or at least equal, our rights in the analog world.[9] For technology design, e2a is shorthand for “edge-to-all,” denoting that our technologies primarily should serve the interests of end users at the network’s edge.[10] Together these two formulas help tether higher level concepts to more concrete outcomes.
In the digital world, four key modes of mediation can help enable the HAACS paradigm, and push back against corresponding elements of the SEAMs paradigm: (1) the ways we experience the world: digital lifestreams; (2) the ways we gain and exert control: trustworthy fiduciaries; (3) the ways we virtualize ourselves: personal AIs, and (4) the ways we connect with each other: symmetrical interfaces.
This paper’s purpose is to shed light on various pathways forward to HAACS-founded futures. Part I lays out the case for shifting away from the current paradigm of unbalanced platforms, pervasive computational systems, asymmetric interfaces, and exploitative SEAMs feedback cycles. Part II establishes why holding incumbent online providers accountable is absolutely essential, but also incomplete. Part III describes what is at stake: human autonomy and agency, the “HAA” of the proposed new paradigm. Parts IV and V examine two particular elements of the “what” of a HAACS research agenda: digital lifestreams, and digital fiduciaries. Part VI focuses on two new agential technology tools: Personal AIs, and symmetrical interfaces. Finally, Part VII and Appendix A together supply the “how” in a detailed action plan to carry out interrelated tasks across multiple domains.
By necessity, this paper is just a sketch, a momentary snapshot of a vast landscape. Much remains to be added, subtracted, fought over, agreed to, and hopefully adopted in some actual places and times in the real world.[11] Crucially, one can reasonably push back against, and even reject, the seemingly dire assessment presented here—and yet still acknowledge that all of us can and should be expecting something appreciably better from the Web.
THE WHY: Refusing to Cede Ourselves to SEAMs of Control
For many people, human autonomy and agency—the liberty to live our lives with meaning and intentionality—are core principles of modern life. And yet, defining these seemingly foundational elements of the self can be challenging.[12] As we shall see in Part II, autonomy can be conceived of as our freedom of thought, while agency amounts to our freedom of action. Taken together, these attributes help define us as unique, purposive individuals, and members of chosen communities.
This section sketches out the multifaceted challenges before us: contending with the unbalanced power dynamics of multisided online platforms, the advent of pervasive all-powerful computational systems, their asymmetric screens, scenes, and unseens interfaces, and exploitative SEAMs feedback cycles. Collectively, one can envision these entities and elements as comprising a Web platforms ecosystem, employing a variety of cloudtech mechanisms, all operating under the SEAMs paradigm.
While platforms are the economic drivers and computational systems the technology instantiations, one must not forget that on all sides there are actual human beings behind each and every action. Web users tend to be drawn to platforms by siren songs of convenience and functionality. The platform ecosystem players—whether grouped together as corporations large and small, or government agencies global, to national, to local—have their own motivations. Typically, their institutional incentives amount to exercising power and control, for their own pecuniary or political or other ends.
While the human story is a timeless one, the economic and technological implements are unique in history. Collectively, these institutions now have the means, and the incentives, on an unprecedent scope and scale, to substitute their own motivations for our hard-won human intentionalities.[13] As Adam Greenfield puts it, “the deeper propositions presented to us” by contemporary digital technologies are that “everything in life is something to be mediated by networked processes of measurement, analysis, and control.”[14] For those who find that vision and those practices that support it problematic, the overarching “why” of this paper promotes one form of a concerted push back.
The Unbalanced Dynamics of Online Platforms
Over thousands of years, economic markets were primarily physical and local.[15] At certain times and in certain places, buyers and sellers connected through farmers’ markets and trade exchanges.[16] These organized gathering spots connected participants to engage in market transactions and other social interactions.
This connectivity function of the ancient Athenian Agora over time became its own standalone business model, deemed by many superior to traditional linear pipeline markets.[17] Over the past twenty years, the platform concept moved into the World Wide Web, and a particular version—the Web platform, and its attendant ecosystem of data brokers, advertisers, marketers, and others—quickly became the prevalent online commercial model.[18]
All platforms create value through matching different groups of people to transact. As Shoshana Zuboff and others have detailed,[19] the version of Web platform ecosystem that dominates today is premised on several sets of players. The User occupies one end, the Platform/Provider of the content/transactions/services the middle, and the Brokers (including advertisers and marketers) the other end.[20] The configuration is simple enough: the Platform/Provider supplies offerings at little to no upfront cost to the User, while data and information gathered about the User is shared with the Brokers, who use such information to target their money-seeking messages to the User.[21] The Platform/Provider in turn takes a financial cut of these transactions.[22]
It is increasingly common to note that in this Web platform ecosystem model, the User is the “object” of the transactions, while the Broker is the true customer and client of the Platform/Provider.[23] Another way of describing it is an unbalanced platform model, where one side obtains decided advantages of power and control over the other.[24] While Web users do receive benefits, in the form of “free” goods and services, they are paying through the extraction and analysis of their personal information—and the subsequent influencing of their aspirations and behaviors by the Platform/Providers and Brokers.[25] However, even today, Web users often do not fully appreciate their decidedly secondary status in this modern day version of a platform.
While network effects and other economic factors make the current Web platform ecosystem model seem all but inevitable, and even irreplaceable,[26] nothing about this particular configuration of players is deterministic. Only two decades have passed since the model first gained traction in the commercial Web.[27] Countless other, more balanced options are available to be explored, where the end user is a true subject of the relationship. Nonetheless, it is fair to say that today’s Web is premised on this unbalanced approach.
The Pervasive Role of Computational Systems
With ready access to financial resources, technical expertise, and our eyeballs and wallets, Web platforms and players in their ecosystems are busy deploying advanced technologies that together comprise vast computational systems. As we shall see, all this tech occupies increasingly significant mediation roles in the lives of ordinary people.
Computational systems are comprised of nested physical and virtual components.[28] These systems combine various overlays (Web portals, social media offerings, mobile applications) and underlays (network infrastructure, cloud resources, personal devices, and environmental sensors).[29] Considerable quantities of data, derived from users’ fixed and mobile online (and increasingly offline) activities, is perceived as supplying the virtual fuel.[30] At the intelligent core of these systems is the computational element itself—what we shall be calling Institutional AIs.
The largest Web platforms—Google, Facebook, Apple, Microsoft, but also Tencent, Alibaba, and Baidu—have woven themselves highly lucrative ecosystems.[31] Importantly, these immensely powerful cloudtech constructs belong to, and answer to, only a relative few in society. The situation is becoming even more challenging as new generations of “intelligent” devices and applications are introduced into our physical environment. These advances include the Internet of Things (IoT), augmented reality (AR), biometric sensors, distributed ledgers/blockchain, and quantum computing, culminating for some in the enticing vision of the “smart world.”[32]
In short, some combination of digital flows, plus physical interfaces, plus virtual computation, plus human decision-making, is what a computational system does. The next two sections will touch on the tightly-controlled user interfaces and the data-based feedback cycles, that together help import our personal data, and export their influences.
The Asymmetry of Screens, Scenes, and Unseens
Computational systems require interfaces. One can think of these as their eyes, ears, and voices, their sensory subsystems. These interfaces are the gateways through which Platforms interact with Users.
Through institutional control over these interfaces, human data and content typically flows in one direction—as we shall see in the “S+E+A” control points of the SEAMs paradigm and its animating feedback cycles. In the other direction flows the shaping influences—the “M” of manipulation in SEAMs. The one-sidedness in transparency, information flow, and control makes the interface an asymmetrical one.
Every day we interact with computational systems via three kinds of interface, envisioned here as digital “screens, scenes, and unseens.”[33] Online screens lead us to the search engines and social media platforms and countless other Web portals in our lives.[34] The Institutional AIs in the computational systems behind them render recommendation engines that guide us to places to shop, or videos to watch, or news content to read.[35] More ominously, these systems (with their user engagement imperative) tend to prioritize the delivery of “fake news,” extremist videos, and dubious advertising.[36]
Environmental scenes are the “smart” devices—cameras, speakers, microphones, sensors, beacons, actuators—scattered throughout our homes, offices, streets, and neighborhoods. These computational systems gather from these interfaces a mix of personal (human) and environmental (rest of world) data.[37] The Ring doorbell placed by your neighbor across the street is but one example.
Bureaucratic unseens are hidden behind the walls of governments and companies. These computational systems render judgments about our basic necessities, and personal interests.[38] These decisions can include hugely life-altering situations, such as who gets a job or who gets fired, who is granted or denied a loan, who receives what form of healthcare, and who warrants a prison sentence.[39]
Interestingly, the progression of interface technologies tends to evolve from more to less visible, or even hidden, forms. What once was an obvious part of the user’s interactions with a system, gradually becomes embedded in local environments and even vanishes altogether. As computer scientist Mark Weiser put it nearly 30 years ago, “the most profound technologies are those that disappear. They weave themselves into the fabric of everyday life until they are indistinguishable from it.”[40]
Human engagement with these receding interfaces also becomes less substantive, as part of a “deep tension between convenience and autonomy.”[41] From typing on keyboards, to swiping on screens, to voicing word commands, to the implied acceptance of walking through an IoT-embedded space—the interface context shapes the mode and manner of the interaction. In systems parlance, the feedback loops become more attenuated, or disappear altogether.[42] Traditional concepts like notice and choice can become far less meaningful in these settings. The tradeoff for humans is exchanging control for more simplicity and ease.
In these contexts, technology moves from being a tool for those many sitting at the edge, to becoming its own agent of the underlying cloudtech systems. Interfaces can remove friction, even as they also can foreclose thoughtful engagement. While this progression in itself may well bring benefits, it also renders more muddled the motivations of the computational systems operating quietly behind the screens, scenes, and unseens.
The Exploitations of SEAMs Feedback Cycles
Finally, computational systems require fuel—steady streams of data that in turn render compensation to players in the Web platforms ecosystem. At the platform’s direction, with its pecuniary motivations, the SEAMs cycle has become the “action verb” of the computational system. Per Stafford Beer, “POSIWID,” or “the purpose of a system is what it does.”[43] The SEAMs paradigm is instantiated in exploitative feedback cycles.[44]
SEAMs cycles harness four interlocking control points of the computational action verb. “S” is for surveilling, via devices in the end user’s physical environment.[45] “E” is for extracting the personal and environmental data encased as digital flows.[46] “A” is for analyzing, using advanced algorithmic systems to turn bits of data into inference and information.[47] And “M” is for manipulating, influencing the user’s outward behaviors by altering how she thinks and feels.[48]
The point of this elaborate set of systems is not in the “SEA” control points, which is troubling enough. It is the “M” of manipulation. By focusing primarily on the user data flowing in one direction, we easily can overlook the direction of influence back at the user. These cloudtech systems both import data and export influence.
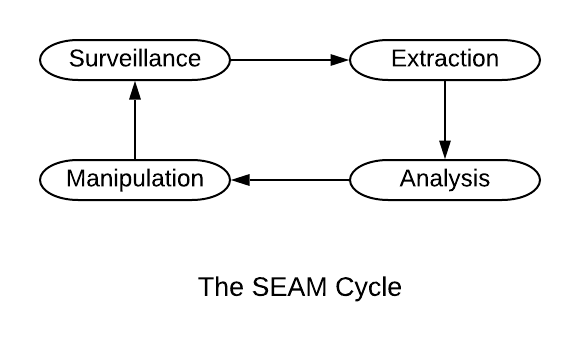 Figure 1
Figure 1
Some may find the nomenclature of manipulation unduly harsh. By definition, to manipulate means to manage or influence skillfully; it also means to control someone or something to your own advantage.[49] Both meanings match what the SEAMs feedback cycles are actually producing.
The institutional imperative is straightforward: create as much influence over users as you can, so you can make as much money as possible. The predominant Web platform ecosystems would forego all the considerable expense and effort of investing in and deploying the “SEA” elements of their computational systems if they were not yielding anything but hugely successful “M” outcomes.
To be clear, those with economic and political power have always wielded technological tools to exploit, and even manipulate, the consumer, the citizen, the human. The history of more benign examples of influence (advertising and marketing), and more pernicious ones (propaganda), is a long one.[50] In consumerist societies, advertising and marketing practices have been used to persuade people to buy goods and services. These practices have morphed over time with technology advances: from newspapers, to radio, to TV—and now to the Web.[51]
What has changed is the sheer power of these new 21st Century ecosystems. “The digital revolution has radically transformed the power of marketing.”[52] The combined reach of the “SEA” control points—the near-ubiquitous devices, the quality and quantity of data, the advanced AI—feeds directly into a greatly-empowered “M” element. There is profound human psychology operating as well in these design decisions. What Zuboff calls the “shadow text” gleaned from human experience helps platforms in turn shape the “public text” of information and connection.[53] Algorithmic amplification of attention-grabbing content further adds to the creation of an online reality.[54] As the feedback cycle progresses, the entire construct constantly evolves, to incorporate ever more subtle nudges, cues, “dark patterns,”[55] and other innovations.
Importantly, SEAMs cycles performed by computational systems, under the direction and incentives of Web platform ecosystems, should not obscure the fact that all of this impressive cloudtech functionality still is being planned and run by human beings. These nested technology and economic systems are only the more visible instantiations of the human drive for control and profit.[56]
Shoshana Zuboff’s in-depth empirical analysis has shed much-needed light on the people behind the algorithms, and their desire to manipulate end users’ behaviors. Senior software engineers and businesspeople at major platform companies confided in her that “the new power is action,” which means “ubiquitous intervention, action, and control.”[57] These Silicon Valley denizens use the term “actuation” to describe this new capability to alter one’s actions; Zuboff labels it “engineered behavioral modification.”[58] She details three different approaches aimed at modifying user behavior: tuning, herding, and conditioning.[59] “Tuning” is the subliminal cues and subtle nudges of “choice architecture.”[60] “Herding” is remotely orchestrating the user’s immediate environment.[61] “Conditioning” reinforces user behaviors, via rewards and recognition.[62]
In all three cases, the end goal is the same: to get a person to do something they otherwise would not do, or, as Zuboff puts it, to “make them dance.”[63] For example, in the case of content delivery to the user, the platform makes more money on content that drives engagement, which can entail dis- or misinformation and extremist content.[64] By programming the system to promote—and amplify—certain kinds of content, the platform is also “programming” the user to accept and interact with that content.
On the selling side, platform operators and their ecosystem partners also can utilize detailed information about the user to extract the maximum amount of money she willingly will part with for a service or product.[65] To the extent this first-order price discrimination technique is employed, it marks a clear case of using extensive knowledge about us, against us.
Importantly, much of this cloudtech activity happens outside our conscious view. Per Zuboff, “there is no autonomous judgment without awareness.”[66] Frischmann and Selinger make a similar point that what they call “techno-social engineering” can shape our interactions, via programming, conditioning, and control engineered by others, often without our awareness or consent.[67]
Moreover, the sense of “faux” agency provided by robust-seeming interfaces leaves many people to believe they remain in charge of their online interactions. When one is unaware of the manipulation, “our unfreedom is most dangerous when it is experienced as the very medium of our freedom.”[68]
If Williams James was correct—that one’s experience is what one agrees to attend to[69]—it would seem to be a rallying cry for the “intention economy” of the twentieth century. Perhaps the converse becomes more apt for the “influence economy” of the twenty-first century—now, whether I agree to it or not, “I am what attends to me.”
One cannot plausibly hope to retain much of one’s independence of thought and of action in the face of such relentless, pervasive, and super-intelligent SEAMs cycles. Nonetheless, today’s technology and economic and political systems are what we have to work with. So those are the best tools available with which to push back.
THE CHALLENGE: Holding the Platforms Accountable Is Necessary—Yet Insufficient
To those who find the above picture troubling, there are two fundamental options. One is to take steps to create greater degrees of accountability for the actions of players in the Web platform ecosystems. The other is to create entirely different ecosystems, based on an entirely different ethos, and overarching paradigm. While this paper calls for pressing forward on both fronts, it will focus primarily on the latter. In brief, as this Part will briefly show, holding the platforms accountable for their actions is necessary, yet insufficient work.
The prevailing policy approaches to countering the negative impacts from Web platform ecosystems amount to minimizing their harmful consequences. Making these systems more accountable to the rest of us, in turn, limits their unilateral reach and authority. This “computational accountability” mode modifies the existing practices of the Web platform ecosystem—including large platform companies, government agencies, and data brokers—while still leaving intact the animating SEAMs paradigm.
Representative steps in the public policy realm to improve computational accountability include: increasing government oversight of large platforms; policing and punishing bad behavior; creating greater transparency to benefit users; enabling more robust data portability between platforms; improving corporate protection of personal data; reducing algorithmic bias in corporate and government bodies; and introducing ethics training in computer science.
Each of these actions is hugely important and necessary to make these computational systems, and their institutional masters, more answerable to the rest of us. As one example, Europe’s General Data Protection Regulation (GDPR) “is a notable achievement in furthering the cause of [protecting] European citizens’ personal data.”[70] Nonetheless, even taken together, such accountability measures may not be enough to significantly alter power imbalances in the current digital landscape.
In each instance, the computational systems themselves still remain largely under the direct control of the underlying platforms and their ecosystem players, with their enormous financial, political, and “network effects” advantages.[71] Platforms’ ability to take on and absorb government accountability mandates may be unprecedented in modern history. Relatedly, larger players often can gain the advantage of “regulatory lock-in,” or the ability to influence, or evade, government rules in ways that smaller players cannot readily duplicate.[72] This threat has been well articulated with regard to the large platforms’ ability to comply (or approximate compliance) with GDPR.[73]
Moreover, regulatory solutions based on making incumbent players more accountable typically rely primarily on behavioral remedies—what could be considered “thou shall not” or “thou shall” injunctions.[74] Such regulations can be difficult to define, adopt, implement, and enforce.[75] Such behavioral remedies also tend to leave existing power asymmetries in place.[76] Users’ current struggles with “consent fatigue” from cookie consent notifications is only symptomatic.[77]
At bottom, an exclusive focus on accountability may well end up conceding too much to the status quo. As Catherine D’Ignazio and Lauren F. Klein observe in their book Data Feminism, accountability measures by themselves can amount to “a tiny Band-Aid for a much larger problem,” [78] and even have the unintended consequence of entrenching existing power.[79] Core aspects of the prevailing SEAMs paradigm, and its enacting business models, may well remain intact. Even fighting to grant users the ability to monetize their own personal information can be seen as accepting the reductivist Silicon Valley credo that “personal data is the new oil.”[80]
Some Limits of the Privacy Concept
The concept of privacy is an important tool for protecting the self. Still, the SEAMs feedback cycles are one reason why privacy, as commonly understood, is insufficient on its own to adequately protect ordinary humans from unwanted incursions.
To the average person on the street, the concept of one’s privacy as an individual has been sold as an irrelevant luxury. Scott McNealy of Sun infamously remarked back in 2003 that, “you have no privacy—get over it.”[81] While at Google, Eric Schmidt posited that, “if you have something that you don’t want anyone to know, maybe you shouldn’t be doing it in the first place.”[82] These types of comments suggest that those within the Web platform ecosystem hope to instill in each of us a sense of resignation, if not outright shame, to counter the natural desire to protect one’s personal and private self from intrusive eyes.
Not surprisingly, then, two common refrains one hears regarding platform privacy are that “they already have all my data anyway,” and “I have nothing to hide.” In both cases, however, the person likely presumes that the platforms are utilizing a linear mechanism to acquire pieces of their daily life—their name, their credit card numbers, an unflattering photo, their favorite beer—to create a profile from which the platform will simply try to sell them some goods and services.
As we have seen, however, this folk understanding understates the threat. The sheer shaping function of the dynamic, feedback loops-based “M” element in the SEAMs cycles is not well understood. Players in the Web platform ecosystem do not (only) want to discover something you might want, in order to sell it to you. The goal of the purveyors of SEAMs cycles is to export their influence, conscious or otherwise.[83] They want to make you do certain things—buy goods and services, provide content, take a stance on a controversial issue, cast a vote for a certain political candidate—that they want you to do.[84] Their end game is to actually manipulate and alter one’s thoughts (autonomy) and behaviors (agency), because it makes for better business.[85] Using privacy policies as a shield to defend one’s sphere of intimacy and vulnerability, would not appear to be much of a match for determined SEAMs cycles-based manipulation.
Further, the concept of privacy typically extends only to what has been thought of as personal data. Other forms of data—from shared, to collective, to non-personal—seem ill-suited to individual privacy.[86] Yet the SEAMs cycles churn through all types of data, with potentially pernicious impacts on human society. These impacts include the externalities stemming from entities exerting control over such data in ways that may not harm specific individuals, but still harm society in general.[87]
In short, then, reducing the harmful actions of an already-powerful status quo is vital work, but, by definition, produces only partial societal gains. The point is not to abandon these efforts, but to supplement them. These accountability-type policies then offer a much-needed, but slightly ill-fitting, shield. The times may be calling as well for introducing a sturdy sword. A complementary paradigm, of enhancing real-world human autonomy and agency, would more directly challenge that same cloudtech-enabled status quo.
THE PROPOSED WHAT: Enabling Human Autonomy and Agency
If public policies premised on platform accountability are not sufficient to fully protect us from harm—let alone allow us to promote our own individual and collective interests—what other options are available? If with accountability regimes the rallying cry has been “Do Not Track Me,” the more urgent injunction offered here is “Do Not Hack Me,” or even “Do Not Attack Me.” The remaining part of this paper suggests practices and actions founded on what is called the HAACS paradigm.[88] The premise is that I should have available to me the entities and technologies that will allow me to “hack back” at the SEAMs paradigm, and its benefactors.
This section will briefly explore the “HAA” element of the paradigm—autonomy and agency for ordinary human beings. The point of this all-too-brief exercise is to establish the considerable stakes involved when encountering the full force of the early twenty-first century’s Web platform ecosystems. Part IV then will dig into our (pre)conceptions about data. Part V will unpack how digital fiduciaries can bolster human autonomy and agency in the digital world. Part VI then discusses two discrete edgetech tools—Personal AIs and symmetrical interfaces—that can channel these priorities as supporting “CS” elements. Part VII and Appendix A provide a detailed, provisional action plan, the “how” for bringing into reality each of these five related elements.
As noted above, economic and technology systems are rooted in basic human behaviors. No Web platform company or computational system, no asymmetric interfaces or SEAMs feedback cycles, have any meaning outside the purview of the human motivations sustaining them. Relatedly, we cannot hope to push back against the SEAMs paradigm and its supporters, without a firm grasp on what in fact we are fighting for. The section below proposes to start with the human in the middle, and then work forward.
Importantly, the HAACS paradigm is an unfinished work. It is more a promising research agenda, than a complete and final concept unto itself. At this early stage, HAACS represents an adaptable stance, better evolved and fleshed out by many people, in organic ways, both bottom-up and top-down. What follows here, and in the remaining sections, should be taken as an open invitation to engage in the conversation.
Why should we begin here? Because any fruitful conversations about technology and economic and social systems are best grounded in the humans behind them all.
For many thousands of years, philosophers and others have been debating the finer points of whether and how we human beings are truly free. What has emerged in some quarters is what amounts to a rough consensus: we are neither totally free beings, nor are we totally determined automatons. Between those two poles remains a vast area of contention.
With a nod towards the experts, I will first appropriate two often-employed terms of autonomy and agency, and attempt to give them a bit of new life. The guides here will be drawn from cross-disciplines, such as phenomenology (in philosophy),[89] the 4E school of cognition for our embodied, embedded, enactive, and extended selves (in cognitive science),[90] and self-determination theory (SDT) (in psychology).[91]
At the outset, the literature suggests that autonomy and agency can be viewed as two separable attributes of the human self.[92] Autonomy is self-direction, self-determination, and self-governance.[93] It amounts to the freedom to decide who one wants to be, in one’s thoughts and intentions. By way of contrast, agency is behavior, interaction, the capacity to take action.[94] It amounts to the freedom to intervene and act in the world. At the extremes, a child’s simple robot can be said to have some agency—without much autonomy—while a prisoner in a dungeon has some autonomy, without much agency.
The two concepts of autonomy and agency amount to deciding to do something, versus being able to do it. The freedom to create and determine your own motivations, versus the freedom to act upon them.[95] They can be considered two flavors of human liberty, and perhaps two fundamental ways to define the human self and her unique identity.[96]
At the same time, thought and action form part of a continuum of human beings existing in the world. The two concepts are closely intertwined, and can be mutually reinforcing, or degrading. They also are matters of degree, across a blend of the (supposed) inner and the outer worlds. To capture this notion of continuity and blending, from here forward we will refer to a singular process of exercising “human autonomy/agency.”
For example, one purchases a new vehicle. What steps were involved in that decision-making process? Likely at the outset some vague, even unconscious or subconscious suppositions about the necessity of a car in modern society, emotional desires to own a certain “sexy” brand, and mental calculation of a cost/benefit analysis. At some point the musings become an intention, marked by certain outward behaviors (checking online for specific offers) and actions (obtaining a bank loan), that lead to the parking lot outside a local automotive dealer. Wherever autonomy ends and agency begins, a robust mix results in a brand-new hybrid vehicle parked in the driveway.
Human autonomy/agency also can be explored through the prism of two kinds of liberty. Freedom “from” something is considered the negative form–for example, in autonomy as the freedom from outside coercion and manipulation.[97] Freedom “for” something is deemed the positive form–for example, in autonomy as the freedom to develop one’s own thoughts and actions in creative ways.[98]
Both forms of freedom are not absolutes, but subject to a variety of internal constraints (urges, needs, genes, personality) and external constraints (environment, society, nature).[99] These constraints present differently in each culture, and each individual. The key is whether and to what extent humans have some element of conscious sway over these “heteronomous” influences. Within the self determination theory (SDT) school of human psychology, for example, autonomy “is not defined by the absence of external influences, but by one’s assent to such inputs.”[100]
There are also important external bounds that communities can and do place on the exercise of human agency. Traffic lights, restaurant dress codes, not yelling “fire” in a crowded theatre—examples abound. More fundamentally, societies continually deal with the challenging tensions between freedom and justice. Human freedom is relativistic. As Camus put it, “[a]bsolute freedom is the right of the strongest to dominate,” while “[a]bsolute justice is achieved by the suppression of all contradiction: therefore it destroys freedom.”[101] These tensions are best worked out in inclusive, democratic processes.[102]
While constraints on freedom present to some as significant limitations, they do not foreclose all degrees of independence. Indeed, in important ways, our constraints are necessary to our ability to experience our freedoms. Taylor notes that “the only viable freedom is not freedom from constraints but the freedom to operate effectively within them…. Constraints provide the parameters within which thinking [autonomy] and acting [agency] might occur.”[103] Further, as Unger has argued, we are always more than what our circumstances otherwise would dictate.[104] And the process is ceaseless. “The complex processual nature of the self—always changing and developing, always reflecting on and transforming itself, [is] never complete.”[105]
Finally, autonomy/agency is not limited to certain cultures, or certain times. While the ways these attributes of self can be expressed are innumerable and subject to different kinds of outside influences, empirical evidence demonstrates that these still constitute universal and core human capabilities for thinking, and being, and acting in one’s world.[106]
As Part B will explore, human autonomy/agency does not exist in a vacuum. By nature we are mediating creatures, constantly interacting with, and filtering, the world through our sensory and conceptual systems. That mediating role takes on even greater importance with the advance of digital technologies, where technical interfaces and other tools are taking over more of the filtering work of our biology-based mediation systems.
Feedback is what allows information to become action, provides “the bones of our relationship with the world around us.”[107] As embodied beings, we exist within webs of mediation shaped by our social interactions.[108] Mediation processes are a part of our organic constitution, as our bodies and brains and minds constantly filter in the meaning, and filter out the meaningless.[109] As social beings, we have a long history of delegating our mediations to third parties[110]—news sources, government bodies, religious institutions, trusted friends, and the like.
The point is not somehow to avoid all forms of mediation (an impossible task), but rather to understand better how they operate, and then take a hand in controlling the flows and interfaces that make up the mediation processes. Using the noise/signal duality from information theory,[111] the objective is to achieve human meaning, by elevating the signal while depressing the noise.[112] Better yet, one can align trustworthy outside mediators to help compensate for our cognitive biases and shortcomings, rather than prey on them as exploitable weaknesses.
A useful image for human mediation could be that of an enclosing bubble, with semi-permeable barriers. By affirmatively pushing to expand the bubble outward, one can accept and bring into oneself certain aspects of the world. A new friend, a challenging book, an educational documentary, an inspiring church service. In contrast, by deliberately pulling back to contract the bubble inward, one rejects and moves away from unwanted aspects of the world. When one is in charge of this process, one can control to some degree one’s autonomy of thought and agency of action. When others are taking more such control over these continual self-expansions and -contraction processes, the actual human at the center is less in charge.[113]
When trust is embedded in a mediating relationship, one can engage in processes of opening up to a broader range of outside influences.[114] This type of intention-driven openness contrasts with enclosure by default (through one’s fear or anger), as well as forms of “faux” openness defined by others that end up acting against one’s better interests.
Unger has written cogently about this lifelong dialectic process, as “being in the world, without being of it.”[115] He urges us to overcome the duality between exposure and sterility, or as he puts it, “engagement without surrender.”[116] To the point, “It is only by connection with others that we enhance the sentiment of being and developing a self. That all such connections also threaten us with loss of individual distinction and freedom is the contradiction inscribed in our being.”[117] In brief, we are “[c]ontext-shaped but also context-transcending beings. . .”[118]
From fire, to the printing press, to the digital computer, humans have employed technologies to modify and control the external environment, as well as augment human capabilities. Technology is embedded in, and can help open up and enhance, our sensory and other bodily/conceptual/social systems. If the human mind truly is an extended and embodied locus of processes,[119] then technologies reside within that mediated zone.
Technology has become a consistent mediator of its own in our lives. This “mediatization” came in waves: from the mechanical, to the electrical, and now the digital.[120] As with other human forms of mediation, there is little to be gained by closing ourselves off completely from technology as mediator. The point is not to shun it, but to control it. As Verbeek puts it, “Human freedom cannot be saved by shying away from technological mediations, but only by developing free relations to them, dealing in a responsible way with the inevitable mediating roles of technologies in our lives.” [121]
Crucially, technology is not some deterministic, inevitable force or trend. Nor is it some value-neutral tool. Technologies serve as proxies of the persons or entities wielding them. Choices made by designers—what functions to include or exclude, what interfaces are defined or not, what protocols are open or closed—have a profound effect on how the technology is actually used.[122]
This certainly has been the case with the Internet and its overt design principles.[123] To the countless software engineers developing the Internet over several decades, its key attributes amount to the goal of connectivity (the why), the structure of layering (the what), the tool of the agnostic Internet Protocol (the how), and the end-based location of function (the where).[124] In each case, design was founded on specific engineering principles grounded in human values. In particular, the end-to-end (e2e) principle describes a preference for network functions to reside at the ends of the network, rather than in the core.[125] This design attribute reflects a deliberate value statement that disfavors certain functions—such as packet prioritization from the lower network layers—while engendering greater ease of use and openness for the upper application layers.[126]
Other design choice examples are premised on simplistic conceptions of transparency that rely on the outmoded “conduit model” of communications. In these cases, information is assumed to simply move from sender to receiver without any filters or translation processes.[127] Human beings and technologies generally do not work in that manner—unless (like the Internet) they are designed that way.[128]
What Couldry and Hepp call the “mediated construction of reality” is the insight that “the social is constructed from, and through, technologically mediated processes and infrastructures of communications.”[129] Importantly, these technology processes of mediation are necessary outcomes of economic and political forces.[130] Under today’s mediation conditions, they find, “the social construction of reality has become implicated in a deep tension between convenience and autonomy, between force and our need for mutual recognition, that we do not yet know how to resolve.”[131]
The deepest tension, Couldry and Hepp conclude, is between the necessary openness of social life, where we develop our lives autonomously, and “the motivated (and in its own domain, perfectly reasonable) enclosure for commercial ends of the spaces where social life is today being conducted.”[132] As we have seen with the SEAM feedback cycles, players in platform ecosystems employ the Web’s technologies as a means to harness mediation processes that can influence users, directly or indirectly.
One challenge comes where technology’s many mediations harbor opaque influences. Web ecosystem players mediate in at least two ways. First, via their proffered forms of interface, these entities can provide the outward illusion of autonomy and agency.[133] Second, by creating repetition that fosters a sense of familiarity, these entities can train our behaviors to fit the intentions of the underlying systems.[134]
So, humans filter the world through a blend of biology and technology-based interfaces. While most of us are born with a healthy mix of natural mediation tools, we also design and create new technologies to extend and enhance the reach of those tools. As Part C will explore, these mediation tools take on added importance as humans use them to derive personal meaning from the daily flow of experience. Our self/world mediations help constitute us as autonomous and agential beings in the world.
Mediation tools do not exist in a vacuum. As filtering agents, our personal identities are constantly changing and evolving blends of the autonomous and agential.[135] For many, this means that our lives constantly flow with meaning. “[H]uman experience is characterized by our embedding in webs of meaning arising from our participation in systems of many sorts. . .”[136] Much of the “meaning” may arise, not only from conceptual thought, but as well from the raw feelings derived from our ancestral brains, based on genetic inheritance, sensory inputs, internal bodily inputs, and action dynamics.[137]
Our lived reality is a unique bundle of experiences, interactions, and relationships—a fluid mix of the past (memories), the present (moments), and the future (intentionalities). Hopes, fears, and aspirations are woven together with the experiences of others—family, friends, strangers, communities of interest. This feeling of autonomy and self-determination, as represented in the action of agency, “is what makes us most fully human and thus most able to lead deeply satisfying lives—lives that are meaningful and constructive—perhaps the only lives that are worth living.”[138] My own term for this human experience of the (potentially) meaningful flow of space and time is the individual’s lifestreams.
In phenomenology and the 4E school of cognition, concepts like self and world, the inner and the outer, inhabit more a continuum than a duality.[139] Relational boundaries have been called “the space of the self … the open-ended space in which we continually monitor and transform ourselves over time.”[140] This circle of inner and outer spaces never-endingly turns in on itself, as “a materially grounded domain of possibility that the self has as its horizon of action and imagination.”[141] As Brincker says:
As perspectivally situated agents, we are able to fluidly shift our framework of action judgment and act with constantly changing outlooks depending on the needs and opportunities we perceive in ourselves and our near surroundings in the broader world…. [W]e continuously co-construct and shape our environments and ourselves as agents…. [142]
If we follow the 4E school of cognition, then the role of natural and technological mediation processes is even more important. The scope of human cognition is extracranial, constituted by bodily processes (embodied), and dependent on environmental affordances (embedded and extended).[143] If the self and her environment essentially create each other, whether and how other people and entities seek to control those processes becomes paramount.
Importantly, the twinned human autonomy/agency conception should not suggest a form of isolation or solipsism. The stand-alone, solitary, “cast-iron,” and completely independent individual is simply an unsupported philosophical relic of the past.[144] In fact, there are both individual and collective forms of autonomy and agency. In SDT psychology, “[c]ollective autonomy is experienced by processes of endorsement and decisive identifications.”[145] Our relationships in the world make us social creatures; our connections to the world make us cultural creatures. Our mode of meaning is more than individualistic; it is collective. Ultimately, human autonomy/agency embraces the liberty to define and enact one’s own semi-permeable boundaries between self and rest of world.
As the brief introduction above shows, concepts of human autonomy and agency, mediation and meaning, are broad and deep. Yet even this cursory treatment shows how our technology systems can be engineered to further, or constrict, the essence of our shared humanity.
Below, Parts IV, V, and VI shift to focusing on four key loci where society, technology, and the twinned human autonomy/agency elements intersect. Part IV delves into conceiving of “data” as digital lifestreams, which opens up productive new conceptual spaces for governing and managing these experiential flows of meaning. Part V then turns to the role of trustworthy fiduciaries in promoting our digital life support systems—and fulfilling the human governance formula of D≥A. Finally, Part VI explains how the advanced edgetech tools of Personal AIs and symmetrical interfaces together can transform digital spaces from closed windows to open doors—furthering the proposed design principle of edge-to-all, or e2a.
While each element is important in its own right, combining them in a true ecosystem-building approach best harnesses their impact. Indeed, employing systems-informed approaches will maximize the relative gains from the interwoven elements.[146]
THE PROPOSED WHAT: HAACS and Digital Lifestreams
Part III examined the extraordinary richness of the human experience, including the human and technological systems of mediation that help us create meaning and purpose in our lives. The notion of lifestreams was introduced above as a way of capturing the essence of living in a world that provides opportunities to express our autonomy of thought and agency of action.
This Part combines the lifestreams concept with the digital environment presented by advanced computational systems. Section A explains how the thing we have come to call “data” is an ill-fitting shorthand that fails to capture the varied, social, contextual, and situational aspects of our digital lifestreams. This Section briefly considers alternative data narratives to the prevailing extractive metaphors. Section B applies these insights to conversations about economic doctrine, where data is better perceived as a collective good resource. In that same section, fiduciary law will be posited as a superior legal governance mechanism that provides solid foundations for human and constitutional rights regimes in digital spaces.
What exactly is data? This section proposes some alternative conceptions to the prevailing, commodity-based assumptions foisted by the platform companies—and even many of their critics.
Perhaps few words in the 21st Century have been so widely employed, debated, misunderstood, and abused than “data.”[147] While its provenance extends back several hundred years—well before the annals of modern computer science—data from the beginning has been a rhetorical concept, deriving much of its meaning from the times.[148] Indeed, for some 200 years, the notional West and global North have been building a world based on the collection and analysis of data.[149] Today, the thing we call data increasingly is being defined for society by corporations and governments with their own stakes in the outcome.[150] Such definitional exercises tend to obscure the reality of the Web’s SEAMs feedback cycles and the very human motivations that drive them.
The concept of digital lifestreams described below seeks to take back some of that definitional authority. That alternative conceptualization begins in section 1 with a grounding in the more humanistic term described above as lifestreams, which embraces experiential flows about myself, and my relationships and interests in the world. The “digital” is added to represent the technology-based encasement of those flows. Section 2 briefly summarizes the follow-on possibilities for new data analogies and narratives. Section B then addresses some of the governance implications from the economic, management, and legal perspectives.
Technically speaking, data is a string of binary digits (1s and 0s) intended to connote a piece of reality.[151] Data is a well-known term from computer science, often conceived as something for entities to manage in an information lifecycle.[152] Over time, concepts of data have been imported into the real-world of human beings. Each of our lives now is being represented in digital code, by platform companies, data brokers, government agencies, and many others.[153] Three foundational points warrant initial emphasis.
First, while computers are digital devices, human beings and the environments we inhabit are analog.[154] By definition, that means the world produces an endless series of signals representing continuously variable physical quantities.[155]
Often we forget that the digital language of ones and zeroes is merely the encoding—a translation, a rendering, an encasement—and not the reality it seeks to portray. We can experience first-hand how a live musical performance exceeds the highest fidelity Blu Ray disc—let alone the poorly-sampled streaming versions most of us are content to enjoy as is. So, one plausible definition of data is the digital encoding of some selected aspect of reality.
Many aspects of our analog life can be rendered in “digitalese,” from the somatic (physical), to the interior (thoughts and feelings), to the exterior (expressions and behaviors), to the conventional identifiers (social security numbers).[156] Each of these is a certain form of data intended to denote aspects of the individual’s relational self. Importantly, this means that the very nature of “data” eludes the monolithic. Indeed:
The process of converting life experience into data always necessarily entails a reduction of that experience – along with the historical and conceptual burdens of the term…. Before there are data, there are people… And there are patterns that cannot be represented – or addressed – by data alone.[157]
To be clear, the formatting shift from analog to digital has brought enormous, tangible benefits to our world. The challenge is to successfully translate life’s ebbs and flows into coherent signals that successfully yield useful insights into our humanity.[158] At this early juncture, it is far from clear that the black-and-white conceptualizations of the binary can ever hope to match multihued existence. The ever-present incompleteness and inaccuracy of data may be ubiquitous.[159] And the qualified self may well elude the best encapsulations of the quantified self.
We are more than just the data that others have been gathering about us.
Second, the “production” of data is inherently asymmetrical, because it is accomplished for the purposes of private or governmental bodies that use the data.[160] The authors of Data Feminism have made plain “the close relationship between data and power.”[161] Further, “the primary drivers of data processes as forms of social knowledge are institutions external to the social interactions in question.”[162] Utilizing SEAMs cycles, commercial platform companies seek to build quantified constructs meant to represent each of us. Or, at most, my intrinsic value to them as a consumer of stuff. To them, data is a form of property, a resource, a line item on balance sheets—used to infer and know and shape, to the depths of our autonomy, and the span of our “perceptible agency.”[163] To some, data may even represent the final frontier of the marketplace, the ultimate opportunity to convert to financial gain seemingly endless quantities of the world’s digitized stuff.
This pecuniary conception of data supports the narrow and deep commodification of the quantified self as a mere user or consumer of goods and services. Narrow, because the data lifecycle is answerable primarily to the singular desire to control and/or make money from us. Deep, because of the desire to drill down into who we are at our most fundamental levels—our interior milieu—as revealed in our thoughts and feelings. The SEAMs cycle is engaged to gain as much “relevant” information as possible about us, and then influence or even manipulate our autonomous/agential selves.[164]
Even our somatic self, such as facial features, fingerprints, DNA, voice, and gait, is considered fair game, for the identifying characteristics that can reveal, or betray, us.[165] To date, the predominant use cases of physiological (fixed physical characteristics) and behavioral (unique movement patterns) biometrics have been limited to the security needs of authenticating and identifying particular individuals.[166] While these applications bring their own challenges, some would go further, to probe aspects of the self not voluntarily revealed in outward ways.[167]
For example, purveyors of “neuromarketing” support better understanding consumers by analyzing their personal affect, including attention, emotion, valence, and arousal.[168] Using “neurodata” gathered from measuring a person’s facial expression, eye movement, vocalizations, heart rate, sweating, and even brainwaves, neuromarketers aim to “provide deeper and more accurate insight into customers’ motivations.”[169] Such technology advances pave the way for achieving the Silicon Valley ideal of knowing what a user might want, even before she does.[170] Or, more ominously, implanting that very wanting.
As noted above, a human life is much richer and more complex than the narrow and deep commodification of the Web. Those who engage in “computational” thinking de-emphasize many aspects of the human, such as context, culture, and history, as well as cognitive and emotional flexibility and behavioral fluidity.[171] Presumably these aspects of the “self” have meaning only to the extent that they provide insights into how humans decide and act in a marketplace or political environment. The nuance of the actual human being can become lost in the numeric haze.
If we are to be digitized and quantified, it should be on our terms.
Third, the quantified self can both capture and diminish human insights. Based on the discussion above, our “data” can be envisioned in a number of different dimensions:
Heterogeneous (varied). Data is not one, or any, thing. Instead, as commonly invoked, the word obscures the vast scope and range of its reach.
Relational (social). One’s “personal” data is intertwined with countless other human beings, from family to friends to complete strangers. Our streams are constantly crossing and blending.
Contextual (spatial). Data “bleeds” into/out of surrounding spaces. The physical environment of the collection and measurement can determine whether the data can be interpreted correctly as signal, or noise.
Situational (temporal). Data reflects the reality of a certain time and circumstance, but often no further. A person today is not the same person tomorrow.
These dimensions map well to the many selves we show to ourselves and the world: the personal, the familial, the social, the economic, the political. Importantly, people attach their own significance and meanings to these aspects. As one scholar summarizes the inherent mismatch between data purveyors and the rest of us: “Do not mistake the availability of data as permission to remain at a distance.”[172]
The HAACS paradigm endorses giving the human the means to fully translate her multi-faceted lived self into digital code. That translation could run as broadly and as deeply as the technology allows, and the human accepts, encompassing all dimensions in the flow of personal change and evolution. This means voluntarily introducing the richness of one’s lifestreams to the binary of the digital.[173]
Perceiving the online environment as potential home to one’s digital lifestreams opens up new ways to consider utilizing the technologies of quantification.[174] In breaking away from the monolith of the SEAMs feedback cycles, and accepting the increased blurring of the analog and the digital, we are more in charge of shaping our autonomous self, and enacting our agential self. Then, we can open up creativity, unlock insights, and light up pathways.
Guided by the assistance of one or more trusted intermediaries,[175] the process could focus on what enhances our own human flourishing. Meaning for example a less narrow, less transactional appreciation of digital artifacts—the words and sounds and images we create and gather and share online. Digital lifestreams can provide a more faithful mirroring of one’s constantly shifting internal and external interactions. As such (and perhaps ironically), they promise a more accurate representation of a person’s life than third parties are able to assemble with SEAMs control cycle processes, and their surreptitious surveillance and data gathering and inference engines.
Each human being should have considerable say in whether and how her unique person is presented to herself, and to the rest of the world. For some, this could mean establishing and policing semi-permeable zones of autonomy and agency around oneself. If, however, she chooses to have a digital self, she should be in charge. The resulting vibrant, rich, and ever-changing digital lifestreams can provide a backdrop against which, as analog beings, “we continuously co-construct and shape our environments and ourselves as agents.”[176]
The next section will look briefly at the prevailing extractive narratives around personal data. More organic alternatives will be proposed—including breaths of air, rather than seams of coal.
Creating New Analogies and Narratives
Viewing data with new conceptual lenses opens up novel vistas for further exploration. Digital lifestreams is but one conception of data in our technology-mediated world. As the preceding discussion suggests, we are in desperate need of better ways to conceptualize the stories and practices surrounding our data. Some stakeholders are making the attempt.[177] This section will supply a few additional thoughts.
Framing our data not as things but as flows—an experiential and ever-evolving process—presents a more open-ended and intentional way to conceive of humans. This framing also acknowledges the many ways that “my” data mixes inextricably with “your” data, and the non-personal data (NPD) of our surroundings.[178] In addition, this shift in framing helps move us away from the transactional modes of commerce, and towards the relational mode of human interaction.
Nonetheless, per the dominant theology of Silicon Valley, information about people is perceived to be a form of real property, a resource to be mined and processed and, ultimately, monetized.[179] As Srnicek puts it, “Just like oil, data are a material to be extracted, refined, and used in a variety of ways.”[180] The wording itself gives away the industrial presumption.[181] It “suggests physicality, immutability, context-independence, and intrinsic worth.”[182] Even unwanted bits amount to “data exhaust.”[183] It seems the best counterpoint that advocates can muster is to claim that users should be sharing in the monetization of that non-renewable asset.[184] Data as property however is an unfounded economic concept (supra Section IV.B).[185]
Framing personal information as petroleum product crowds out more humanistic conceptions of personal data.[186] More useful metaphors and analogies are well worth investigating. Grounding ourselves in the ecological, rather than the industrial, would be a marked improvement. Imagining data as sunlight, [187] while a far better conception than data as oil, for some could suggest yet another natural resource to be exploited. That framing also can feel a bit removed from the lived human experience.
One suggestion here is to imagine an organismic analogy for computational systems. The interfaces discussed below (“data extraction”) would be the sensory systems, while the AIs (“data analysis”) would be the nervous systems. What then would best connote the bio-flow of sustaining energy? One compelling image is provided by the respiratory system—the human breath. A constant process of converting the surrounding atmosphere into productive respirations—fueling the organism, but in a sustainable, non-rivalrous, non-extractive manner. The breath sustains many different bodily functions. From the molecules of collective air each of us shares, to individual breath momentarily borrowed, and back again—respiration, like data, mixes the personal and non-personal, the individual and communal. The image connotes an organic feedback cycle, one far different than the extractive SEAMs data cycles employed by platform companies and their partners.
Shifting the Data Governance Perspectives
Moving from the world of narratives and metaphors, next we encounter the necessity of determining ways that governments and markets alike should govern this thing we call data. As described above, the SEAMs feedback cycles embedded in today’s Web entail “users” surrendering data from online interactions, often based on one-sided terms of service, in exchange for useful services and goods.[188] Now, even third parties with whom one has no prior relationship can access and utilize one’s data.[189] Implicit in that model is the notion of data as a form of private property, governed by traditional laws of property rights.[190] The HAACS paradigm invites a fundamental reappraisal not just of data as a concept, but the follow-on presuppositions about ways we would govern that data.
This section first looks at economic framings that better encompass the largely non-fungible, potentially excludable, and inherently non-rivalrous nature of data. I propose relying on legal frameworks grounded in fiduciary doctrine, to fit the asymmetrical power relationship online, and better ground the extension of human and constitutional rights to our digital selves.[191]
If one is to utilize for data something akin to traditional economic principles, an initial question is what kind of “thing” we are talking about. Microeconomists have employed the so-called “factors of production” theory to divide goods and resources into four separate buckets: capital (like factories and forklifts), labor (services), land (natural resources and property), and entrepreneurship (ways of combining the other three factors of production).[192] Based on these traditional categories, data could be one of them, some combination of one or more, its own separate factor, or no factor at all.[193]
A prominent school of thought classifies data as a type of good. Microeconomic theorists classify a good based on answers to two questions: whether it is rivalrous (one’s consumption precludes others from also consuming it), and whether it is excludable (one can prevent others from accessing/owning it).[194] This two-by-two classification scheme yields four distinct categories: private goods, toll goods, public goods, and common pool resources.[195] Most private goods—cars, bonds, bitcoin—are defined as both rivalrous and excludable: one’s consumption eliminates their economic value, and governmental restrictions (usually laws) allow one to keep them away from others.[196]
Data presents an interesting, and likely unique case. First, at least some of what it entails is non-fungible, meaning it encapsulates something with unique value and meaning.[197] Even if every data packet or stream looks exactly the same from the perspective of a computational network, the shards of reality they purport to represent can differ, even minutely, one from another. Data then is not simply a commodity, like a unit of currency, or a barrel of oil, which tends to hold the same value in every situation.[198]
Second, like a private good, data is at least partially excludable; one theoretically can prevent others from accessing and using it. Excludability is not a fixed characteristic of a resource; it varies depending on context and technology.[199] So, data in some cases can be withheld from others.
Third, and crucially, data is also a non-rivalrous good. This means anyone can utilize it, without necessarily reducing its overall value. In fact, multiple uses of the same data—whether individual or collective—can increase its overall utility and value. So, data can gain value with every use and shared reuse.
Microeconomic theory tells us that this “mixed” set of attributes—non-fungibility, potential excludability, and non-rivalry—makes data what variably is called a toll, club, or collective good.[200] Old school examples of a collective good include cinemas, parks, satellite television, and access to copyrighted works.[201] Membership fees are common to this kind of good (hence the “club” and “toll” terminology).[202]
A further economic consideration is the presence or absence of externalities, those indicia of incomplete or missing markets. These amount to the “lost signals” about what a person might actually want in the marketplace.[203] Externalities in the data context translates into what market conditions might be good or bad for certain sharing arrangements.
If it is correct that data is largely a non-fungible and non-rivalrous resource by nature, and potentially excludable by design, there are major implications for how we govern data. We need not accept the too-easy assumptions that data is just another extractive resource, subject to the same commodification as a barrel of oil. The very nature of a non-renewable resource is its rivalrous nature. Data, for lack of a better word, is renewable, like sunshine, or air, or the radio spectrum. Moreover, where oil and other non-renewable resources are found on private lands, they are non-excludable goods. Either way, traditional economics shows that data is more like a collective good than a private good. As will be addressed below, this conclusion suggests different mechanisms for managing data.
The Management: Overseen as Commons?
If data is in fact a collective good, a follow-on question is, how is this particular good to be managed? Typically modern society employs institutions as the “rules of the game”—the particular blend of governmental and market structures to govern a good, service, or resource.[204] Here, what are the respective roles for the market, and the government, in establishing the ground rules for accessing data if treated as a collective good?
Traditional answers would either have the market managing private property (with an important assist from government in terms of laws of access and exclusion), or a public entity managing a public good.[205] A blend of institutional choices is possible as well, from the formality and coercive effect of constitutions, laws and regulations, to government co-regulation, to less formal codes of conduct, standards, and norms. In each case, tradeoffs are inevitable, between (for example) degrees of formality, coercion, accountability, and enforceability versus adaptability, flexibility, and diversity.[206]
While market mechanisms generally are the most efficient means for allocating rivalrous goods, traditional property rights could unnecessarily constrain beneficial sharing arrangements.[207] The non-rivalrous nature of data suggests it could be governed as a “commons.”[208] Importantly, a commons management strategy can be implemented in a variety of institutional forms.[209] Part of Elinor Ostrom’s genius was perceiving the commons as occupying a space between the two governance poles of government and market—what she labelled the “monocentric hierarchies.”[210] Her conception of “polycentric governance” by a like-minded community was intended to address the collective-action challenges stemming from a need to manage common pool resources.[211]
Data also can be likened to other intangibles, like ideas, which can be said to constitute part of an “intellectual infrastructure.”[212] Frischmann notes the difficulty of applying infrastructure concepts to “the fluid, continuous, and dynamic nature of cultural intellectual systems.”[213] The related concept of a “knowledge commons” would govern the management and production of intellectual and cultural resources.[214] Here, the institutional sharing of resources would occur among the members of a community.[215] A similar story may be possible for many data management arrangements.[216]
This brief analysis also reveals one key to the enormous success enjoyed by platforms in today’s data-centric economy. While multiple entities can leverage personal data about a user non-rivalrously, in a kind of multiplier effect, at the same time the user has found it difficult physically and virtually to exclude these same entities from accessing and using her data.[217] In economic terms, the platforms treat one’s data as a commons, to be enclosed within their business models, for their own gain. In so doing, these companies privatize the benefits to themselves, and socialize the costs to others, including society and individual users. Taleb has a name for this phenomenon: these entities lack “skin in the game,” which he likens to avoiding “contact with reality.”[218]
Where economics then can have some rational say, the governance direction seems to be away from private property law, and towards more relational conceptions of resource management, including the commons. Legal governance will be considered next.
The Law: Fiduciary Duties and Human Rights
As noted above, data protection regimes essentially accept as given the current Web ecosystem, and the “transactional paradigm” of reducing human beings to conduits of static data points. Once, however, we make the fundamental narrative shift from the transactional mode to the relational mode, then the governing legal structures and regulations can shift accordingly. What legal frameworks other than private property law can fit this new conception of data?
Fiduciary law is essentially the common law of uneven human relationships.[219] The doctrine is entwined with centuries of equity, torts, and other common law doctrine.[220] Frankel has observed that “throughout the centuries the problems that these laws were designed to solve are eternal, etched in human nature, derived from human needs, and built into human activities.”[221]
Not surprisingly, then, fiduciary law principles are near-universal, having been applied across a vast array of human endeavors. These include agency, trust law, corporate law, nonprofits law, banking, pension law, employment law, bankruptcy, family law, health care, public affairs, and international law.[222] While most often associated with the English common law, fiduciary law also encompasses most major global cultures—such as canon law, Roman law, classical Islamic law, classical Jewish law, European civil systems, Chinese law, Indian law, and Japanese law.[223]
The basis for a fiduciary relationship is straightforward: assigning certain legal and moral obligations to people and entities engaged in exchanges of value with each other.[224] The linchpin is what Tamar Frankel calls “entrusted power.”[225] An individual or entity (the entrustor, or beneficiary) grants access to something of value, to another individual or entity (the fiduciary), for the purpose of having the fiduciary undertake tasks that benefit the entrustor.[226] In these situations, the fiduciary normally has some knowledge, expertise, or other socially desirable capabilities, that the entrustor lacks.[227] Moreover, sensitive information often is revealed in the context of establishing the relationship (or even becomes its basis).[228]
Prime modern-day examples of fiduciaries include the medical profession, the legal profession, and certain financial sectors. Entrustment of power to those providing these kinds of services triggers the obligation.[229]
The fiduciary relationship is based on an entrustor’s confidence that the fiduciary will carry out its duties in ways that will further the entrustor’s interests.[230] The entrustor willingly has made herself vulnerable: by the initial entrustment of something of value, plus the possible follow-on revelation of sensitive information and confidences in order to gain something in return.[231] To that end, it is a duty rooted in asymmetric power relationships between the parties.[232]
The fiduciary can abide by two basic types of duties: care and loyalty.[233] The duty of care obligates the fiduciary to, at minimum, act prudently and do no harm to the entrustor.[234] The duty of loyalty goes further, to require the fiduciary to have no conflicts of interest, and to promote the best interests of the entrustor.[235]
Importantly, while the thing of value over which the fiduciary is granted control often is a form of tangible property, that need not be the case.[236] Because fiduciary law is relational, the “what” is limited only by what is deemed important by the entrustor.[237] In a legal trust, for example, the entrustors’ health care or legal status may be the “thing” at issue. Confidential information is another recognized intangible.[238] The core concept is to protect personal and practical interests, whatever they may be.[239] So, one implication is that the logic can shift from owning data as a form of property, to accessing data as a particular right to control a collective good.[240]
This means that being a fiduciary runs not with property, but with the person and her entrusted confidences.[241] Given the variable nature of data—heterogenous, contextual, relational—this concept of “running with the person and her confidences” can be a crucial underpinning for a fiduciary, law-based doctrine of data governance. For present purposes, the key takeaway is that fiduciary law would appear to be an apt fit to govern personal data and other related sensitive information about oneself.
Constitutional rights and human rights
One of the challenges with both property law and privacy law is that they rely in the first instance on “extrinsic” power emanating from government.[242] Without enabling statutes and regulations, no one’s physical or personal property—or data—is safe from the taking of others. As we have seen, such accountability regimes have their limitations.[243] Societies have come to utilize more foundational and enduring implements, like constitutions and treaties, to wall off certain areas of life from the negative actions of others. The rubric normally used is human rights.[244]
While the law of fiduciaries has traditionally been limited to the private law regime, scholars have recently articulated why and how it can be extended to the public law realm. Due to the enunciated limitations of the social contract theories of government,[245] some scholars have argued for the reinstatement of the concept of the “fiduciary theory of government” to oversee citizens’ relationships to their own governmental institutions.[246] Under this approach, because public officials enjoy a position of entrusted power, they owe obligations comparable to those of agents, trustees, and other fiduciaries.[247]
The United States Constitution itself may appropriately be viewed as a fiduciary instrument, imbuing the power of attorney-like obligations of care, loyalty, and impartiality.[248] Scholars have found “a strong, and perhaps even overwhelming, case for at least looking at fiduciary law as a source of constitutional meaning.”[249] One implication is that the US Government could theoretically be held accountable to its citizens as a bona fide fiduciary.
To some, human rights lack an enduring foundation in current laws.[250] To help fill that perceived gap, fiduciary law has been invoked to apply to human rights vis-à-vis national and international institutions.[251] Under this telling, human rights “are best conceived as norms emanating from a fiduciary relationship that exists between the state and persons subject to its powers, including citizens, resident aliens, and nonresident aliens.”[252] These norms arise from the state’s assumption of sovereign powers.[253] To the extent then that stakeholders are interested in pursuing the concept of one’s digital lifestreams as part of a human-rights framing, fiduciary law could provide some crucial buttressing.
Fiduciary law thus provides a fascinating basis for governing data.[254] It nicely reflects the shift both from transactional to relational mode, and from accountability to agency mode. It provides “skin in the game” on both sides of entrustment-based relationships. It requires degrees of trust and support, that over time can feed back onto each other in positive ways. It “runs with the person” and all her heterogenous, contextual, and relational ways of being in the world. It buttresses those who seek a more certain conceptual footing for constitutional and human rights.
As we will see in the next section, the law of fiduciaries can also be harnessed to play a particularly crucial role on behalf of Web users: as an individual’s trustworthy and supportive intermediary.
THE PROPOSED WHAT: An Ecosystem Anchored by Digital Fiduciaries
The HAACS paradigm seeks to harness from computational systems countless positive impacts on human agency/autonomy. On the “CS” side of the ledger, this means creating ecosystems that include new kinds of information constructs, agential entities, AI applications, and network interfaces. Each of these modalities, in turn, pushes back emphatically against the four basic controlling elements of the SEAMs paradigm.
The goal is not merely to minimize the harms emanating from incumbent technology platforms—hugely necessary work in its own right—but to maximize the positive impacts from newly-formed platforms that we control ourselves.[255] In other words, as examined briefly above, end users can move from a digital world founded largely on negative rights (“freedom from” the bad stuff), to one that rests as well on positive rights (“freedom for” the good stuff).[256]
To the extent the Web platform companies and their supporting ecosystems have been so financially successful, a root cause is the ways they have unilaterally turned themselves into the new intermediaries of the Web. Perhaps it is time to utilize their own mediating technologies to engage in our own form of “countermediation.” As this Part will discuss, one approach is to build what has been called the GLIAnet ecosystem, premised on trustworthy digital fiduciaries.[257] Section A addresses the yawning gaps in trust and support that such entities can address, while Section B unveils the governance and business models that these client-focused digital fiduciaries can take on. Part VI in turn will elaborate on how these entities can arm their clients with various advanced edgetech applications, with a focus on Personal AIs and symmetrical interfaces.
From the perspective of ordinary users, today’s Web is missing at least two crucial components. One is basic human trust. The other is helpful support. Ideally, the two elements can be combined into trustworthy and supportive online relationships that promote the best interests of the human being.
It is a truism that trust is the social glue, the foundational principle that holds all relationships, and binds us together.[258] Challenges with trust are not unique to the online world; this lack has also become increasingly noticeable across other major societal institutions.[259]
According to noted expert Rachel Botsman, there are three basic kinds of trust which have developed over human history.[260] Local trust is the original form between individuals, typically between members of small, local communities.[261] This kind of interpersonal trust in someone is specific and familiar.[262]
The second kind is institutional trust.[263] This flows upwards to leaders, experts, and brands, which traditionally have included large entities such as churches, governments, media, and corporations.[264] To some, institutional trust has been declining due to an increasing number of (or simply more revelations about) scandals and breaches of faith involving these entities.[265]
The third kind is distributed trust,[266] which flows laterally between individuals, enabled by systems, platforms, and networks.[267] Botsman believes this version to be in its infancy, and a source of both potential upside and downside for users.[268] Distributed trust is based on reputation—what someone thinks about you—which Botsman considers to be “trust’s closest sibling.”[269]
Regardless of the particular flavor, lack of trust in entities outside one’s own inner circle should not be surprising.[270] In the online context, a leading cause of distrust is the mismatch in motivations.[271] Too many online entities typically treat those using their services as mere “users,” rather than bona fide customers, clients, or patrons. This objectification carries over to their commercial practices, which rely heavily on the SEAMs control cycles.[272] All of which inevitably leads to a more trust-deficient Web.
Another missing ingredient online is basic support for users. As the Web has become ever more complex, with both threats and opportunities hanging on the next mouse click or voice command, protecting oneself has become ever more challenging.
Again, the mismatch in motivations between platforms and their users creates an erosion in fundamental responsibility –a lack of “skin in the game.”[273] As one example, when Web companies even provide “customer support,” the service is almost entirely reactive, and for most of us a subpar experience.[274] As Botsman puts it, “the online landscape is vastly populated and yet, all too often, empty of anyone to take charge or turn to when it counts.”[275] The buck stops elsewhere.
The basic aim of support is to help me protect myself online—do not track me, do not hack me—and to be responsive to me when something goes wrong. Even better is the kind of support that actively tries to improve my situation. Potential opportunities on the Web abound. Perhaps a provider could analyze and improve my privacy settings on Web browsers and other applications. Update software, patch security holes, manage passwords, provide VPNs, and establish end-to-end encryption. Provide machine-readable guidance on terms of service (ToS) and user agreements, manage online consents, and establish more user-responsive applications. And of course, help me set up and manage my digital lifestreams. Relatively few companies today are providing just a few such offerings.
For the pervasive lack of both trust and support, the root cause is the same: entities who may outwardly claim to act on our behalf, but are financially conflicted from actually doing so. When one is the user, the object, the product, of an online “relationship,” the motivations are to do only as much as necessary to keep eyes glued to screens, with no questions asked.
Perhaps the key is to delegate one’s aspirations for the Web—one’s desire for trustworthy and supportive relationships—to agential third parties. The next section spells out the kinds of intermediaries that can be forged from fiduciary law principles.
Creating Trustworthy Digital Life Support Systems: Digital Fiduciaries
Human beings deserve societal institutions which they can trust to truly serve their best interests, as well as provide tangible support to enable greater human autonomy (thought) and agency (action). One can think of a governance model extending to a new class of “digital stewardship.”[276] In this regard, the common law of equities can be a valuable basis for entities to operate as one particular type of digital steward: client-focused digital fiduciaries, grounding the GLIAnet ecosystem.
As discussed above, fiduciary doctrine potentially provides an important foundation for human rights and constitutional rights as they pertain to our digital selves. The law of fiduciaries can be extended as well to the types of entities we wish to directly engage with as individuals, to foster trustworthy and supportive relationships. In particular, entities operating voluntarily under heightened fiduciary duties of care, loyalty, and confidentiality can fill in the existing market gaps looming between large platform companies and their users.
As part of this proposed new world of “digital trustmediaries,” several models of online agents have been proposed for entities to adopt on a voluntary basis. The digital fiduciary, to be discussed further below, is based on individual agency in an actual fiduciary relationship with a client.[277] The concept is that the digital fiduciary serves a set of clients as a trusted online agent, promoting their data-related interests in highly personalized fashion.[278] This digital fiduciary could be created or evolved in a number of ways. Forming a new profession of trustworthy mediating entities, founded on abiding by such equity principles, is but one possible option.[279]
Another type of digital stewardship model comes from the related common law of trusts. A data trust is based on collective agency over the personal data and information of a specified collective of individuals.[280] Here the entity manages a pool of data on behalf of a community of individuals.[281] Typical examples include the health care data trust, which would enable medical professionals, researchers, and others to access personal health care information.[282] The civic data trust applies a similar collective governance model to the personal and environmental information that is gathered and analyzed in the context of smart cities.[283]
One can imagine people employing a mix of digital fiduciaries (for personal agency), data trusts (for collective agency), and other trustworthy agents to manage their digital lifestreams. For example, a digital fiduciary could handle an individual client’s digital interactions and relationships. That digital fiduciary in turn could negotiate on behalf of its client with a data trust seeking to pool together somatic data for important health care research. The digital fiduciary also could mediate for its clients with the civic data trusts governing the computational systems embedded in “smart city” environments.
Key differentiators separate these fiduciary-based digital stewardship models from the status quo. First, the human being is no longer a mere “user,” but instead a full-fledged client, customer, or patron, with the full rights and protections of a legally-sanctioned and supported relationship. Second, at least some of these new digital fiduciaries and trusts would be able to take on not just the task of avoiding the collection and misuse of one’s personal data and information, but actively supporting all aspects of the clients’ interactions with incumbents and their computational systems. Third, under the heightened fiduciary duty of loyalty, digital fiduciaries in particular would have no conflicts of interest or duty (the so-called “thin” version) and be obligated to promote their clients’ best interests (the “thick” version”).[284]
Of course, having an intermediary is not an entirely self-sustaining proposition. Section 2 below addresses some potential ways that these entities can be founded and funded.
Business models: A wide variety of entities and offerings
In addition to resting on governance models based on fiduciary obligations, the GLIAnet ecosystem acknowledges the prospect of a wide range of business models and other value propositions between intermediaries and their clients.[285] In each case, the participating entity would see benefits from providing digital services to individuals and communities.
The list is lengthy of entities which theoretically could step into a digital fiduciary relationship with clients. Under the right circumstances, traditional corporations could participate in this new ecosystem.[286] These could range from existing service and goods retailers, to news organizations and broadband providers. Other, less “conventional” corporations are available as well, such as b-corps, public/private partnerships, and non-profits. Some of these entities could include credit unions, trade unions, public libraries, and universities.
Another interesting option worth considering is to create a wholly novel type of corporation, the “D-corp.”[287] This for-profit company would be in the business of providing data-based digital services to their clients. Importantly, these digital corporations would be chartered to operate under fiduciary duties of care and loyalty. Potentially the D-corp could become the basis of a new profession of digital fiduciaries.
A diversity of community-based ventures also is possible. These might include data co-ops, data commons, platform cooperatives, and blockchain foundations. In these models, a community governs itself and establishes the appropriate exchanges of value with its members.[288]
A variety of compensation mechanisms are open for exploration, well beyond the status quo of feedback-driven SEAMs cycles and “surveillance capitalism.”[289] In fact, the current advertising and marketing approach has shown increasingly visible viability issues.[290] Higher quality commercial brands may welcome the opportunity to explore alternative, mutually-beneficial arrangements with their customers.[291] Countless other funding models, from monthly subscriptions to per-transaction fees to blockchain utility tokens, also are possible. Targeted government subsidies may be necessary as well, to help avoid creating a new class of digital left-behinds.[292]
In each instance of entities and funding mechanisms, the key question is whether they are willing and able to step into a full-fledged fiduciary relationship with a set of clients or patrons. As will be explored below, there are several possible tiers of digital services and fiduciary duties that can be embraced.
Panoply of “PEP” services and duties
Digital fiduciaries could perform a variety of client services, under varying fiduciary obligations. Collectively, these services and duties amount to providing people with a digital life support system. What follows is but one example of such a system, premised on three separate services/duties phases: protecting, enhancing, and promoting the client and her interests.[293] As will be seen, at each of the three “PEP” phases, an entity’s provisioning of more expansive and technologically advanced sets of services—as data guardian, information mediator, and digital advocate—is paired with heightened fiduciary measures of trustworthiness.[294]
In the Protect Phase, the digital fiduciary can provide fundamental customer protections, focused on engendering greater privacy, enhanced security, and safeguarded online interactions.
Privacy: fully implement legal requirements, such as GDPR, analyze/improve customer’s privacy settings on Web browsers and other applications, and commit to not surveilling or tracking the client.[295]
Security: update software, patch security holes, manage passwords, provide VPNs, and establish end-to-end encryption.[296]
Interactions: shoulder more daunting cognitive burdens regarding the customer’s dealings with third party websites and applications, such as providing machine-readable guidance on terms of service (ToS) and user agreements, managing online consents, and establishing more user-responsive applications.[297]
In all services provided in Phase I, the digital fiduciary would operate under a general tort-like duty of care (do no harm), as well as a fiduciary duty of care (act prudently).[298]
Enhancing without Conflicts: Information Mediator
In the Enhance Phase, the digital fiduciary could act as a filtering conduit, through which flows all of the client’s online life (one’s digital lifestreams). This role could include establishing a virtual zone of trust and accountability to ward off intrusive actions, project the client’s own ToS to the Web, flag use of bots and other automated influence software, develop client “alt-consent” restrictions and choices, introduce symmetrical network interfaces, and send tailored alerts about disinformation such as deep fakes.[299]
In addition to operating under both duties of care, the Phase II entity would also be bound by the “thin” version of the fiduciary duty of loyalty (no conflicts of interests).[300]
Promoting Best Interests: Digital Advocate
In the Promote Phase, the digital fiduciary “could employ even more advanced and emerging technology tools to fully protect, enhance, and promote the client’s interests.”[301] These could include personal data pods, localized cloudlets, sovereign identity layers, portable connectivity, and modular devices.[302] As will be discussed below in Part VI, one Phase Three function could be an individualized computational agent, sometimes called a Personal AI.
In addition to operating under both duties of care, and the thin duty of loyalty, the entity would utilize the “thick” version of the fiduciary duty of loyalty (promote best interests).[303]
Obviously digital fiduciaries and clients can together explore any number of desired functions in each of these three phases. Importantly, as the agent-client relationship progresses, a likely outcome is a virtuous “macro” feedback loop.[304] As greater levels of trust and support are established over time, the client can consensually share more personal information, which in turn spurs the addition of still more empowering service offerings.
Part VI will describe how digital fiduciaries—operating within a GLIAnet ecosystem, premised on the HAACS paradigm—can further empower their clients by providing them with advanced edgetech tools. Two chief examples explored below are Personal AIs in Section A, and symmetrical interfaces in Section B.
THE PROPOSED WHAT: Edgetech Implements of Personal AIs and Symmetrical Interfaces
Starting from a fresh perspective on personal data as digital lifestreams and the role of digital fiduciaries in building genuine trust and support, this Part turns to the edge-empowering technologies that can be employed to enhance human autonomy and agency. The two specific edgetech applications described below are Personal AIs—algorithmic agents that operate on behalf of ordinary humans—and symmetrical interfaces—mediating processes that emanate from empowered humans, rather than terminate at disempowered users.
The key design attribute shared by these and other GLIAnet technologies is what is called here the “e2a” (edge-to-all) principle. As mentioned above,[305] a truly revolutionary hallmark of the Internet’s engineered architecture is the end-to-end (“e2e”) principle. Unlike the modern communications and information networks that preceded it, the e2e principle preferences intelligence and control at the ends of the network, rather than the core.[306]
While the e2e principle (and other design attributes) have enabled the Internet to support and promote a vast range of human activities,[307] that same openness to innovation and creativity also allows certain actors, such as companies operating multisided platform ecosystems, to benefit disproportionately.[308] In essence, these entities have managed to occupy one “end” of the e2e relationship with Web users, and “tilted” their cloudtech-based platforms to primarily serve their own pecuniary ends.[309]
The point here is not to somehow undo the hugely impactful and successful end-to-end principle. Rather, we should focus on constructing and implementing overlay technologies designed to better harness the intrinsic power of e2e design. In this case, however, the overlay brings a significant difference: it overtly and decidedly shifts network control and intelligence to one node, occupied by the end user at the “edge.” As a result, those at the network’s edge would be enabled to initiate and directly manage many of their Web interactions—hence, the edge-to-all design principle.[310] As we will see below, shifting to an e2a mindset opens the door to new edgetech implements that can help bring the HAACS paradigm to life.
To date, AI systems have been in the hands of the relative few, utilized by companies and governments alike as the “Analysis” element of SEAM cycles. This section proposes turning around the conceptual telescope, by giving humans more of a direct say in the role of computational systems. In short, each of us should have access to our own Personal AI.
Problem-solving machines have been known since early Egyptian times. An algorithm essentially is a set of rules for solving a problem.[311] Today, the algorithms of machine learning, fed by massive amounts of data, dwarf any such machinery of the past.[312]
Artificial intelligence networks being created, trained, and deployed by corporations and governments can be best thought of as “Institutional AIs.” These algorithmic elements of computational systems churn through data to discern insights that in turn can help develop tactics to get people to make one set of decisions over another.[313] As such, Institutional AIs pose a fourfold societal challenge: they are pervasive, consequential, inscrutable, and (in)fallible.[314]
Pervasive: Institutional AIs lurk behind every screen, scene, and unseen in our lives.[315]
Consequential: Institutional AIs make decisions that affect every one of us, from online recommendation engines, to speech bots in our living rooms, to decision engines in every corporate and government office.[316]
Inscrutable: Institutional AIs often utilize deep neural networks and machine learning–based systems, virtual “black boxes” where ordinary humans (and even expert software engineers) often cannot perceive or understand their operations and the basis for their outputs.[317]
(In)fallible: Institutional AIs raise major societal issues—regardless of their accuracy. Where their insights and inferences are correct, it means they have amassed highly sensitive correct profiles, which could be used to our detriment.[318] When their insights and inferences are flawed, it means they have amassed highly sensitive incorrect profiles, which also could be used to our detriment.[319] The choice seems stark enough: either the all-knowing panopticon of Orwell’s 1984, or the bureaucratic fog and confusion of Kafka’s The Trial. Or, the worst aspects of both.
With the rise in particular of virtual assistants, such as Alexa, Google Assistant, Siri, and Cortana, consumers now are purchasing first mobile devices, and more recently home devices, that include AI-based agents. In reality, these virtual agents waiting in the background “scenes” are an integral part of the SEAM cycles that these companies deploy. This means there is usually a single entity truly calling the shots: the corporation, with its financial motivations. Again, as with the online “screens” of our mobile phones, the human being in the home environment of her own living room is the object of the technology.
Many futurists tout existential concerns about AI taking over the world—”AI vs. Humans.” The more near-term reality is less dramatic, but no less concerning. In what could be thought of as an “essentialist” threat, humans armed with Institutional AIs will be seeking to control the rest of us. Instead of machines becoming more like humans, their hoped-for outcome is humans who behave more like machines—whether serving the interests of governments (political power), or corporations (financial gain).[320] As proposed below, perhaps our best recourse is to fight back with similar algorithmic technologies, but on our own terms.
Advanced AI systems need not be the sole provenance of large, non-fiduciary institutions motivated solely by their own financial or political gain. As explained in Part II, attempting to impose accountability measures on “Institutional AIs,” such as combating algorithmic bias and flawed data sets, is a necessary but insufficient remedy.
One answer? Each human being should have the ability to possess one’s own highly individualized virtual intelligence, to provide both online and offline support. These computational agents—Personal AIs—would exist on one’s devices, managed by the digital fiduciaries described above. Technically, the computation function and data storage can reside locally, rather than being managed from a distant cloud. Practically, the Personal AI can be wholly separate from the control of any Institutional AIs.[321] Such local control and virtual separation would be consistent with the edge-to-all (e2a) design principle described above.
The Personal AI can act as an agential go-between with Institutional AIs operating behind the interfacial screens, scenes, and unseens. This form of agency translates into taking specific actions on behalf of the individual. Among other tasks, [322] a Personal AI could:
Manage and protect its clients’ online and offline digital lifestreams;
Interpret website/app terms of service (ToS) and other policies, generate tailored consent responses, and broadcast the client’s own ToS to the Web;
Monitor health status;
Implement financial transactions;
Set individual preferences and defaults for client’s dealings with news feeds, social networks, retail sites, and other online interfaces;
Ensure that Web-based recommendation engines are serving relevant information, and not harmful content, such as “fakes” or addictive videos;
Mediate the terms of immersive digital experiences with AR/VR/MR platforms;
Negotiate directly with environmental devices—smart speakers, facial recognition cameras, biometric sensors—and authorize, limit, or block access from surveilling and extracting personal data; and
Challenge the efficacy of financial, healthcare, law enforcement, and other impactful algorithms for bias and other flaws that would harm its client.
In all such cases, the Personal AI could be a critical agential platform, operating between the human being and the vast range of Institutional AIs and SEAM control cycles spanning our digital world. In particular, by training on the client’s data, and using advanced machine learning techniques, the Personal AI over time can find new ways to promote the client’s best interests.[323] A cinematic example is JARVIS, Tony Stark’s eponymous digital assistant operating within his Iron Man exoskeleton.[324]
One intriguing option to consider is to have Personal AIs fill the function of what Professor Todd Kelsey has called the “Missing Advocate.”[325] In countless situations, Institutional AI are rendering decisions without any recourse on our part.[326] Kelsey asks whether each of us should have the right to engage these Institutional AIs via our own Personal AI, in any situation where one’s significant interests are involved or at risk.[327] As with using governance mechanisms to rebalance the power asymmetries between platform ecosystems and users, here e2a design-based technologies can be employed to tilt the computational playing field more in the direction of the ordinary human being.
The Personal AI concept has the potential to evolve into an entirely new support system—the essential trusted digital agent. Among other benefits, these applications could well become the “killer apps” of a more trustworthy, agential Web. What will be necessary to make this vision a reality, however, includes the software code that links together the underlying systems—as described below.
Creating AI Protocols and Setting Standards
Computer science professionals have begun providing important public leadership to develop the necessary standards to enable Personal AIs. In its December 2017 report on Ethically Aligned Design for autonomous and intelligent systems (“A/IS”), IEEE explained that people should have “some form of sovereignty, agency, symmetry, or control regarding their identity and personal data.”[328] Such “digital sovereignty” entails the ability “to own and fully control autonomous and intelligent technology.”[329] IEEE expressly endorses the concept of a Personal AI:
To retain agency in the algorithmic era, we must provide every individual with a personal data or algorithmic agent they curate to represent their terms and conditions in any real, digital, or virtual environment…. A significant part of retaining your agency in this way involves identifying trusted services that can essentially act on your behalf when making decisions about your data…. A person’s A/IS agent is a proactive algorithmic tool honoring their terms and conditions in the digital, virtual, and physical worlds.[330]
The IEEE notes that this A/IS agent role includes educator, negotiator, and broker on behalf of its user.[331] Moreover, individuals separately should be able to create a trusted identity, a persona to act as a proxy in managing personal data and identity online.[332]
At the IEEE, work is already underway to build out the necessary software standards for Personal AIs, via the P7006 working group.[333] However, much more will likely be necessary. In particular, some incumbent platform companies may well resist the introduction of digital agents, and their enabling trustworthy intermediaries. Such resistance could extend to refusing to engage in meaningful commercial transactions with providers of Personal AIs or supply them with access to necessary platform inputs. Policymaker interventions may well become necessary, including to create new opportunities for more symmetrical client-side interfaces. These new types of mediation processes are discussed below.
Linking to One’s World: Symmetrical Interfaces
Symmetrical interfaces constitute another set of edgetech tools and applications bringing more power and control back to the digital edge of the network. As explained above, and in section 1 below,[334] digital interfaces typically deployed by Web companies both facilitate the ease of end user engagement and constrict a wide variety of other user behaviors. This section proposes some new e2a design–influenced approaches around these designed shortcomings. Three examples discussed in Sections 2, 3, and 4 below are establishing “edge-push” and “edge-pull” interfaces with the Web, requiring robust interoperability and other functional inputs vis-à-vis Web platforms, and arming people to become smarter citizens as they engage with “smart city” environments.
As noted earlier, technology mediates between human beings and our experiences.[335] Robust feedback between people is “the keystone of the user-friendly world.”[336] Problems emerge when one or both sides of the mediation lack proper feedback, so they are “not feeling the stakes.”[337] These problems are pervasive within Web platform ecosystems.
Interfaces are thresholds that connect and disconnect in equal measure. They are “the point of transition from one entity to another.”[338] While scenarios vary, in each case there are specified gateways which control whether and how we can interact with other people.
In Web-based technologies, “interface” is the name given to “the way in which one glob of code can interact with another.”[339] They are points of presence—physical, virtual, or conceptual—at boundaries where information signals can flow between different systems.[340] Over time, Web interfaces have been developed to provide a “user experience” (UX), typically by pushing that experience in the user’s direction.[341] Representative examples include graphical user interfaces (GUIs), voice-controlled interfaces, gesture-based interfaces, and public forms of application programming interfaces (APIs).
As we have seen above, the result at present is a mix of interfaces melded into our up-close screens, our environmental scenes, and our bureaucratic unseens. The issue, of course, is that those with the technical power can use it to establish interfaces as “control regimes.”[342] Not merely technical portals, “in the user-friendly world, interfaces make empires.”[343] Unsurprisingly, the Web user’s interactions are limited to what the website or application authorizes, and no more. This can include creating the illusion that an interface supports human autonomy/agency.
User interface limitations become more problematic when fronting Institutional AIs. From curating the news, to diagnosing illnesses, to determining who gets a loan, or a job, or a jail term—these systems amount to hugely consequential decision machines. And for the most part, they operate from behind interfaces designed and implemented by their institutional masters. SEAMs feedback cycles also run most effectively (from the operators’ standpoint) when the user is complicit, or unaware, or even absent.
In far too many cases online, the ordinary human has only limited transparency or voice, and no actual recourse.[344] This designed shortcoming leads to the further challenge of the conjured illusion of autonomy/agency. From the perspective of the average person, interfaces to these systems can seem deceptively controllable—local, physical, and interactive—even as the mediating processes themselves are far-removed, virtual, and unidirectional.
The next three sections look at some tangible edgetech applications that can give ordinary humans a mediating voice to match their digital experiences. These include online interfaces that center on the client (rather than the server), reciprocal network interoperability with Web platforms, and direct human-to-system interactions in smart vehicle and city environments.
Achieving Symmetry: Setting Rules of Engagement
Systems designers utilizing a HAACS paradigm can change the current one-sided dynamic. The opportunity is two-fold: (1) modifying existing interfaces so that the human being has a viable means of engaging directly with computational systems, and (2) designing new interfaces to maximize the human’s ability to shape her own “user” experiences.[345] The emphasis should be on interfaces that promote autonomy (freedom of thought) and agency (freedom of action). Or, in more technical terms, interfaces should satisfy the proposed edgetech design principle of edge-to-all functionality.
The initial step is to recognize the opportunity to conceptually reset the asymmetry, and then instantiate the e2a design principle in actual technology interfaces. These elements can include the computational element (as with the Personal AI discussed in Subsection VI.A.2., infra), the identity layer, the interfaces, and the data itself.
In the case of interfaces, two primary modalities operating under the e2a principle can more fully empower the individual. They are introduced here as “edge-pull” and “edge-push” capabilities.
“Edge-pull” modalities allow the individual to bring the Web’s computational systems and other resources directly to her. Two examples are creating one’s own news and social feeds from disparate sources, and directing credit scoring companies to access (but not collect) one’s personal data where it resides locally.
“Edge-push” modalities allow the individual to send her own commands and requests to designated sites on the Web. Two examples are broadcasting one’s own terms of service through the browser, and operating one’s own universal shopping cart at disparate retail websites.
These two interface modalities have gained notable champions. The OPAL project, launched by Sandy Petland and others at MIT, enables the edge-pull functionality, by bringing computational systems to the personal data—rather than the other way around.[346] This helps keep the data secure from server breaches, and away from online purveyors of SEAMs cycles.
The VRM project, launched by Doc Searls at Harvard University, is a well-known leader in edge-push thinking.[347] Searls explains how each of us should want to be the first party in a relationship with websites and apps (the primary and active instigator), rather than the second party (the passive recipient).[348] In this case, the other side of the interface would need to accept our terms of service, abide by our privacy policy, and consent to our preferred ways of interacting. [349] In so doing, this active first party role allows us to engage in a conversation—question, object, negotiate, and perhaps reach a mutual agreement.
With both edge-push and edge-pull interfaces, the current Web client-server paradigm is flipped on its head. Among other benefits, by utilizing the appropriate online interfaces, an individual can set her own identity screen to establish protective virtual boundaries. The individual then is able to project herself into the network, opening up new points of bilateral interaction and negotiation. A healthy mix of edge-pull and edge-push interfaces then would allow one to create “mini” positive feedback loops between networks.[350] System designers know that such positive feedback loops have a highly agential impact: “to perturb systems to change.” And in the process, the individual can escape the constraining world of UX design, to define one’s own “HX”—human experience.
Such intentional connectivity can be premised on the end user—likely with the help of digital fiduciaries and Personal AIs—managing her relationships with others online.[351] The end result can be the deployment of networked interfaces that operate as open doors, rather than narrow and opaque windows. One key requirement however will be a robust interoperability regime that allows us to connect, and interact with, incumbent platforms.
Functional Openness: From Interface to Interop
A symmetrical interface is only as good as the interoperability behind it—the two-way means of interacting with other underlying networks. Interop constitutes the somewhat unfashionable network plumbing of software standards and protocols.[352] As one example, for a Personal AI to “talk” directly with an Institutional AI, there must be an accepted means of communication and an agreement to act upon it.
The basic interop fabric is already there to support robust two-way, e2a interfaces. After all, the Internet is a splendid example of an interconnected “network of networks.”[353] Symmetrical interfaces can mirror that same peer-to-peer architecture: my system speaking on equal terms with your system, in a reciprocal manner. What would change is the current overlay of unidirectional interfaces leading to tightly controlled platforms.
While voluntary agreement on the operative protocols and standards would be optimal, there may well be a role for governments to play in smoothing the path for such agreement. Regulators could introduce a mix of tailored market inputs and incentives that would open up portions of underlying platform resources. These might include system-to-system interconnection, robust interoperability (at the different layers of data, computation, identity, and mixed/augmented reality), and data delegability and mobility (from platforms to selected mediators).[354]
Some in the United States Congress have not overlooked this particular option. As a salient example, the proposed “ACCESS Act“ incorporates key functional openness measures aimed at large platform companies.[355] Introduced in the U.S. Senate in October 2019, the bill encompasses two agency-bolstering elements consistent with the HAACS paradigm.[356] First, as virtual infrastructure, the bill would require the platforms to provide interoperability and data portability, via transparent and accessible interfaces suited for both users and third parties.[357] Second, as human infrastructure, the bill would allow users to delegate their digital rights to “third party custodians,” operating under a duty of care. [358]
Environmental Scenes: a Call for Smart Citizens
The environmental “scenes” created all around us by digital technologies present opportunities for amazing individual and societal benefits. In the case of autonomous vehicles, and smart cities, however, too many questions about the agential role of humans remain unanswered. Below, we will briefly examine some promising ways forward.
While much has been written about the Internet of Things (IoT), few note how those billions of devices, hooked into millions of computational systems, provide the ordinary person no realistic opt-out option. And yet, the human on the scene is assumed to be transformed into merely a passive user, now operating instead in the “real world” environment.
Take the rental of an autonomous vehicle.[359] Should you and your family be involved in a crash, it would be useful to know who programmed its safety priorities—and why. Was it the insurance company? The car rental store? The automobile dealer? The automobile manufacturer? The original “default” software programmer? A midnight hacker? Each clearly has its own incentives, that do not always align well with the actual human involved on the scene.
And yet, the individual has no place in that potentially convoluted decision tree.[360] There is no obvious opportunity to engage, to question, to negotiate, to challenge, to object, to seek recourse—in other words, to exercise one’s autonomy/ agency. Without such a mediating process in place, there is no viable way to opt out of the prevailing SEAMs control cycles.
Similarly, in the typical “smart city” environment, drivers, pedestrians, and others at most may receive some transparency in how systems make use of data and some accountability in how systems safeguard such data.
Agential baby in the Quayside bathwater
An early pioneer of the “smart city” was Alphabet’s Sidewalk Labs project in the Quayside neighborhood of Toronto, Canada.[361] As first proposed in October 2017, the project carried the potential to provide benefits to citizens and visitors that included enhanced security, environmental monitoring, and more efficient deployment of government resources.[362] Nonetheless, as the project unfolded over two and a half years, open questions arose, including about possible uses and misuses of data, and the project’s governance.[363] In May 2020, citing economic conditions arising from the COVID-19 pandemic, project director Daniel Doctoroff announced that Sidewalk Labs was shutting down its Toronto project.[364]
Whatever one’s viewpoint on the ultimate demise of the Quayside neighborhood build, there are at least two potentially useful takeaways that should not be lost from the experience.[365] First, Sidewalk Labs launched the Digital Transparency in the Public Realm (DTPR) project, tasked with creating icons and signage that would allow pedestrians to understand what kind of function was being employed by a particular environmental device.[366] Such a “consent through signage” system greatly increased transparency for passersby, but left those with questions or concerns about the sensors little recourse, other than to depart the area.
As it evolved over time, however, the project included a concerted outreach to designers and others to “advance digital transparency and enable agency.”[367] Intriguingly, DTPR’s initial focus on transparency shifted to a phase two devoted to engendering greater accountability for the underlying system’s actions.[368]
In the last few months before the Quayside project was terminated, the DTPR team went further still. Using co-design sessions, charrettes, small group discussions, and prototyping, the team sought to investigate opportunities for actual human agency—in essence, direct human-to-interface interactions.[369] Even interoperable chatbots and Personal AIs were discussed and tested for feasibility.[370] If this agency phase had been successfully pursued, creating these kinds of e2a symmetrical interfaces would have opened up many new spaces for digital affordances and real human autonomy/agency.
As it turns out, DTPR remains very much alive. The open- source project is now being stewarded by an emerging coalition of organizations led by Helpful Places,[371] whose co-founders steered DTPR during their tenure at Sidewalk Labs. The “new” DTPR now stands more appropriately for “Digital Trust for Places and Routines.”[372]
Second, the Sidewalk Labs project touched on another HAACS dimension: governance of the system itself. Over some eighteen months, Sidewalk Labs began exploring the creation of what it first labelled a “data trust,” then a “civic data trust,” before settling on the nomenclature of an “urban data trust” (UDT).[373] Crucially, Sidewalk Labs made it clear that the UDT model would not be a trust in a legal sense–meaning, no trustees operating under express fiduciary duties. [374] Not surprisingly, the shifting approaches attracted public resistance, including from Waterfront Toronto itself.[375]
Whatever the company’s motivations, the reactive, shifting, and top-down nature of its approach to governance likely was unhelpful.[376] This reversal was unfortunate in at least one respect, however: it precluded a more open and inclusive debate about the precise mechanisms and processes that could comprise a successful civic data trust. For example, a civic trust could have been devised so that a citizen’s own digital fiduciary would be able to interact in the digital environment on her behalf—through the very chatbots and Personal AIs that were being explored in parallel via the DTPR process. In essence, the back-end of the project’s governance could have benefited from more fruitful connections with those developing the front-end of agential interface technologies.
Much as Personal AIs enable ordinary people at the network’s edge to challenge the “Analysis” mode of the SEAMs control cycles, symmetrical interfaces are necessary to enable us to push back against, and even opt out from, the “Surveillance and Extraction” modes of the SEAMs cycles. By extension, these kinds of edgetech interfaces interfere as well with third parties’ wide-open opportunities at “Manipulation.” These two examples of e2a-designed technologies do not however exhaust the list of possible agential technology applications.
Other Edgetech Applications and Policies
While Personal AIs and symmetrical interfaces together can better protect and promote the ordinary human’s digital life, other technologies operating pursuant to the edge-to-all design principle similarly can provide agential services at the proverbial “edge” of the Web. These edgetech tools include self-sovereign identity layers, localized cloudlets, personal data pods, decentralized applications, and more.[377]
Public policy can also play an instrumental role. As with symmetrical interfaces and interoperability, other functional openness inputs, if well-defined and implemented, could unlock market opportunities for trustworthy intermediaries to provide advanced tech tools. Additional structural, behavioral, procedural, and informational safeguards may be necessary as well to promote healthy digital marketplaces.[378]
This article has recited the pitfalls of the SEAMs paradigm and proposed an alternative of the HAACS paradigm. As Part VII explains, Appendix A tees up an Action Plan designed to turn conversations and concepts into reality.
THE WHO/WHERE/WHEN/WHICH: An Action Plan for Promoting a New HAACS Paradigm
Appendix A below contains a suggested Action Plan to further develop the HAACS paradigm. The emphasis is on building and implementing those ecosystem components that incorporate the values of human autonomy and agency.
The connective tissue to these proposed initiatives is putting people more in charge of their digital destinies. As a viable alternative to the SEAMs paradigm, we can work collectively to introduce a new HAACS paradigm of empowered human beings wielding their individual and collective liberties via computational systems. In the process, we can enhance our digital lives, both online and offline, in myriad ways.
To advance the HAACS paradigm, this article has examined human governance based on the “D≥A” formula, and technological design based on the “e2a” principle. Beyond these proffered acronyms, however, the real story is only beginning.
More specifically, for each of the five dimensions discussed above—the “HAA” component itself, plus digital lifestreams, digital fiduciaries, Personal AIs, and symmetrical interfaces—the Action Plan specifies ways to mix and match useful components. The Plan highlights those initiatives that are most foundational. The expectation is that, over time, the Plan will serve as a flexible and iterative record of the key actions necessary to create new ecosystems premised on the HAACS paradigm.
“Before there are data, there are people. . . .”
– Catherine D’Ignazio and Lauren F. Klein
For those many intriguing possibilities that may lie beyond—or even within—the current global pandemic, Rebecca Solnit’s words are especially salient: “Disaster sometimes knocks down institutions and structures and suspends private life, leaving a broader view of what lies beyond. The truth before us is to recognize the possibilities visible through that gateway and endeavor to bring them into the realm of the everyday.”[379]
In the future that is now, simply turning over to large Web platform institutions one’s freedoms of autonomy and agency need not be the status quo. The SEAMs paradigm of control can be challenged and with time even overcome. Fully apprehending the role of the SEAMs paradigm, vis-à-vis our human autonomy/agency, can be beneficial in at least two ways. By laying bare the countless ways we are being influenced by external sources, we can take steps to hold the underlying systems more accountable for the harms against us. Additionally, the freshly uncovered SEAMs paradigm provides a ready target for the effective countermeasure of a new paradigm, such as HAACS. In the process, a virtual arms race is in the offing.
Stakeholders can plant a flag on a bold new vision of enhancing human power and control in the computational era. This work should include defining, developing, and supporting separate but related measures to promote autonomy and agency: digital lifestreams, trustworthy fiduciaries, and edgetech tools such as Personal AIs and symmetrical interfaces.
Together, we can help ensure the availability of those social, relational, virtual, and linkage infrastructures to support robust autonomy/agency for all human beings. Humans and machines and institutions then can exist together on a far more level playing field. With the bulk of the humans (more) firmly in charge.
Appendix A: An Action Plan for Promoting a New HAACS Paradigm
This Appendix presents a partial list of the “Hows,” suggested initiatives to develop ecosystems that promote human agency. The initial set of initiatives would deepen our basic understanding of the linchpin to all the technologies that follow: human nature. Without better grasping the respective roles of autonomy and agency (the “HAA” elements) in defining and evolving the human self and its social institutions, our technologies (the “CS” elements) cannot hope to live up to their potential to enhance human flourishing.
There are countless ways to mix and match the necessary components of a robust HAACS paradigm-based ecosystem. Despite the complexity of coordinating across different fast-evolving sectors, discrete dependencies and foundational work can be identified. While not exhaustive, the following list hopefully conveys some of the necessary scale and scope of creating new agential ecosystems founded on digital fiduciaries and edgetech applications.
Definition. Work with experts to produce well-grounded definitions of guiding concepts, such as autonomy, agency, heteronomy, lifestreams, human mediation, technological mediation, and trust.
Research. Conduct empirical and conceptual research, grounded in relevant disciplines such as human psychology, 4Es cognition, neuroscience, sociology, history, ecosystem governance, and philosophy of technology.
Convenings. Bring together experts to discuss pertinent issues, and devise/deepen constructive frameworks for human autonomy and agency.
Outreach. Educate policymakers, technologists, and other influencers on the benefits of human-first technology policies and practices.
Alliances. Found coalitions of like-minded entities to further develop and advocate for the human autonomy/agency space.
Definition. Flesh out the basic concept of digital lifestreams, in contrast to more traditional ways of conceiving of digital/analog systems, and personal data/ information/knowledge.
Narratives. Explore and promulgate compelling alternative framings, metaphors/analogies, narratives, and scenarios for user data, including digital lifestreams.
Research. Investigate certain traditional economic theories of data as a factor of production, including: data as labor (DaL), data as capital (DaC), data as resource (DaR), data as entrepreneurship (DaE), a blend of factors, its own unique factor (such as data as tokens (DaTs)), or other pertinent conceptualizations.
Governance. Conduct and promulgate research on potential governance models, including the economic structures of private/public data commons, and using fiduciary law as basis for governing digital human rights/constitutional rights.
Collaboration. Create an alliance of a wide variety of stakeholders to define and articulate the concept of digital lifestreams.
Outreach. Expand awareness of the digital lifestreams approach to data.
Investment. Make the financial case that consensual access to digital lifestreams creates new market opportunities, potentially for adtech and martech interests.
Advocacy. Include the digital lifestreams concept in policymaker discussions, and potentially in legislative vehicles.
Campaigns. Create public awareness about the personal and societal benefits of framing one’s life experiences as lifestreams suited to agential digital translation.
Human Rights. Introduce the concept of digital lifestreams as a component of international digital human rights.
Definition. Work with experts to establish detailed nomenclature and concepts to define digital stewardship, permissioned systems, authorized agents, key elements of a trustworthy third-party agent, the digital fiduciary of individualized data agency, and the data trust of collectivized data agency.
Duties. Utilize representative use cases and other tools to translate ethical obligations of stewardship, and fiduciary obligations of care, loyalty, confidentiality, and good faith, into the context of real-world digital challenges.
Convenings. Collaborate to bring together groups of experts exploring and developing action plans to develop an ecosystem of trustworthy digital mediators.
Research. Provide theoretical analyses, real-world investigations, and empirical studies of trusted entities. Include historical, psychological, and ecosystem mapping perspectives in areas such as: contesting systemic power asymmetries, generating human trust in institutions; exploring categories and powers of legal fiduciaries and trusts (physicians, attorneys, credit unions, librarians); determine potential roles for new digital corporations (“D-corps”), and other forms of digital ecosystems stewardship; and uncover realistic opportunities for promoting human autonomy/agency.
Prototyping. Develop prototypes of specific types of fiduciaries, including data trusts, civic data trusts, and digital fiduciaries. Connect fiduciary types to particular use cases (for example, access to individual and collectivized data) and preferred outcomes. Enlist potential candidates to experiment with different trust elements.
Outreach. Engage with practitioners, activists, academics, artists, and others to develop and implement wide-ranging vehicles for communicating the message of digital fiduciaries.
Alliance. Create a coalition of like-minded entities to work together on promulgating many of the core governance elements of an ecosystem of trustworthy digital fiduciaries, including governing principles.
Certification. Explore prospects for creating a self- or third party-certification regime of trustworthy digital fiduciaries.
Professional Code of Practice. Explore prospects for creating a professional body of digital fiduciaries, including a code of conduct or practice that incorporates specified fiduciary duties of care, loyalty, and confidentiality.
Inclusivity. Guarantee a diversity of perspectives by creating inclusive multi-stakeholder groups and processes to develop the governing frameworks for trustworthy third-party intermediaries.
Accessibility. Confront the existing “digital divide” by working to ensure that unserved/underserved human populations have meaningful and affordable access to trustworthy third-party agents.
Ecosystems. Seek out potential “anchor institutions” to consider serving as trustworthy digital fiduciaries.
Investment. Demonstrate to funding communities the sizable market opportunities to invest resources in trustworthy digital fiduciaries.
Thought Leadership. Provide thought leadership to influence policymakers to adopt computational agency for humans as a core public policy objective.
Advocacy. Serve as an educational resource to policymakers crafting laws and regulations, such as the ACCESS Act, which enable trustworthy digital agents and other mediaries.[380]
Definition. Develop the core concepts and elements of a Personal AI.
Collaboration. Work with companies and other third parties (non-profits, universities) to create proof-of-concept Personal AIs that meet core human agency standards. An illuminating example is Stanford University’s Almond Project.[381]
Convenings. Establish regular meetings with would-be collaborators to identify and tackle key Personal AI ecosystem dependencies.
Research. Initiate research agenda to identify chief technical components of a Personal AI, including edge computing infrastructure,[382] on-device, off-cloud applications,[383] federated learning,[384] advanced AI chipsets,[385] zero knowledge proof algorithms,[386] 5G wireless connectivity, and other technology advances.
Transparency. Require that all important societal conversations about Personal AIs occur in open and accessible public fora.
Conduct. Help would-be agential entities develop codes of practice to ensure core capabilities are provided by Personal AIs to their human clientele.
Campaigns. Build a grassroots movement with entities such as the Mozilla Foundation, per its impact goal of more trustworthy AI in consumer tech.[387]
Training. Work with groups instilling human ethics into computer science educational curricula,[388] with emphasis on heightening human autonomy.
Safeguards. Develop effective policies and guidelines to help ensure that Personal AIs are created, deployed, and utilized in non-harmful ways.
Certification. Devise and launch accountability measures, such as certification bodies, to assess whether/how Personal AIs meet new code of practices regimes.
Standards. Continue to create industry standards, such as IEEE P7006, to foster the initial deployment of Personal AIs.[389]
Ecosystems. Develop a holistic approach to computational agency for humans, led by Personal AIs as part of a broader spectrum of technologies such as self-sovereign identity layers, localized cloudlets, and personal data pods.
Human rights. Introduce the concept of Personal AIs as supporting self-sovereign agency as part of international digital human rights.
Norms. Promote new social norms regarding Personal AIs’ interactions with Institutional AIs — such as the Right to Recognize, the Right to Query, the Right to Negotiate, the Right to Correct, and the Right to Be Left Alone.
Definition. Develop detailed definitions of symmetrical interfaces and open interop that include the data, computational, identity, and virtual reality layers.
Research. Further develop and utilize the proposed e2a design principle, to explore forms of human/tech mediations.
Collaboration. Work with platform companies to voluntarily implement standardized symmetrical interfaces and open interop regimes for users and trustworthy third parties. The Data Transfer Project presents one opportunity.[390]
Policy. Determine the useful “lessons learned” from governmental regulation of interfaces and interop in the telecommunications and other regulated sectors.
Standards. Work with industry standards bodies to develop software and standards regimes necessary for multi-layer open interoperability.
Advocacy. Engage with government bodies to incentivize the availability of basic interconnection, interoperability, data mobility, and third party delegability rights.
Campaigns. Work with artists and others to develop educational vehicles for promoting to more general audiences the vision and use cases from more robust symmetrical interfaces. Examples could include creating a 55th anniversary update to Douglas Engelbart’s 1968 “Mother of All Demos.”[391]
Appendix B: SEAMs Accountability, vs. HAACS Agency: A Cheat Sheet
| Modality | SEAMs
Accountability |
HAACS Agency |
| Policy | ||
| Regulation type | Behavioral (shall/shall not do) | Functional (shall enable) |
| Regulatory focus | User protection/privacy | Human empowerment |
| Regulatory example | Algorithmic bias | Layer interoperability |
| Legislative example | GDPR (Europe) | ACCESS Act (US) |
| Legal instrument | Property law | Fiduciary law |
| Governance | ||
| Entity legal duty | Care (avoid harm) | Loyalty (promote benefits) |
| Platform participants | Users and brokers | Clients and agents |
| Platform participation | Opt-out | Opt-in/opt-alt |
| Economics | ||
| Third party interactions | Transactional/transience | Relational/continuity |
| Business externalities | Internalize the negative | Internalize the positive |
| Control points | ToS and consents | Mediating processes |
| Technology | ||
| Network hub | Web servers | Web clients |
| Basic units | Bits and data | Digital lifestreams |
| One’s AI agent | Google Assistant, Alexa | Personal AI |
| One’s interfaces | Their screens/scenes | My screens |
| Data metaphor | The new oil | A breath of fresh air |
- * Richard Whitt is president of GLIA Foundation, founder of the GLIAnet project, and a former longtime policy director with Google. He wishes to thank in particular Brett Frischmann and Todd Kelsey for their insightful reviews of earlier drafts of this article. ↑
- . See Nassim Nicholas Taleb, The Black Swan (2010) (describing highly improbable but sizable threats). ↑
- . See Michele Wucker, The Gray Rhino (2016) (describing highly obvious but ignored threats). ↑
- . Donella Meadows, Thinking in Systems: A Primer 145 (Diana Wright ed., 2008). ↑
- . Id. at 145–65. ↑
- . Id. at 153–59. ↑
- . Id. at 162. ↑
- . Id. 163–64. ↑
- . Richard Whitt, Digital Stewardship: An Introductory White Paper, DocSend (July 28, 2020), https://docsend.com/view/en2guc7dm6qksaa7 [https://perma.cc/24T2-PN6R] [hereinafter Whitt, Digital Stewardship] (discussing the D≥A formula); see also Richard Whitt, The Internet’s Untapped Potential, Medium (July 29, 2020), https://medium.com/oasis-protocol-project/the-internets-untapped-potential-4d16b5107a50 [https://perma.cc/V2TF-9S3T]; Richard Whitt, A Human-Centered Paradigm for the Web, Medium (July 20, 2020), https://medium.com/@whitt/a-human-centered-paradigm-for-the-web-640b8ebf86ef [https://perma.cc/CHK9-WWU8] [hereinafter Whitt, A Human-Centered Paradigm for the Web]. ↑
- . See Richard Whitt, Secure Data Tokenization, Medium (Nov. 3, 2020) https://medium.com/oasis-protocol-project/secure-data-tokenization-7b730357b03e [https://perma.cc/X2XV-XVH4] (citing Richard Whitt, Blockchain 3.0: An Introductory White Paper (Nov. 3, 2020) https://docsend.com/view/isrhqk352adykdpz [https://perma.cc/8BJ8-QRCK]). ↑
- . See generally, GLIAnet, www.glia.net [https://perma.cc/X5Y9-3CMJ]. ↑
- . See, e.g., Sarah Newman, AI & Agency Across Domains, AI & Agency (Aug. 2019), https://ai-and-agency.com/ [https://perma.cc/BE6E-FY9E] (agency invites many open questions and inconsistent assumptions). ↑
- . See Richard Whitt, Old School Goes Online: Exploring Fiduciary Obligations of Loyalty and Care in The Digital Platforms Era, 36 Santa Clara High Tech. L.J. 75 (2020) [hereinafter Whitt, Old School Goes Online]; see also Richard Whitt, Hiding in the Open: How Tech Network Policies Can Inform Openness by Design (and Vice Versa), 3 Geo. L. Tech. Rev. 28 (2018) [hereinafter Whitt, Hiding in the Open]. ↑
- . Adam Greenfield, Radical Technologies: The Design of Everyday Life 308 (2018). ↑
- . Whitt, Hiding in the Open, supra note 12, at 66. ↑
- . Id. ↑
- . Id. ↑
- . Id. at 66–68; see generally Whitt, Old School Goes Online, supra note 12, at 102–05. ↑
- . See Shoshana Zuboff, The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power (2019); see also Tim O’Reilly, WTF? What’s the Future and Why It’s Up to Us (2017); Roger McNamee, Zucked: Waking up to the Facebook Catastrophe (2019). ↑
- . Whitt, Hiding in the Open, supra note 12, at 68. ↑
- . Id. ↑
- . Id. at 66–70. ↑
- . Whitt, Old School Goes Online, supra note 12, at 102–05. ↑
- . Id. ↑
- . Zuboff, supra note 18, at 293–97. ↑
- . Whitt, Hiding in the Open, supra note 12, at 69–70. ↑
- . Id. at 68. ↑
- . Chapter 4 Computational Systems, FAS, https://fas.org/man/dod-101/navy/docs/fun/part04.htm [https://perma.cc/M6GV-EZ2Y] (last visited Oct. 18, 2020). ↑
- . Whitt, Hiding in the Open, supra note 12, at 69; Whitt, Old School Goes Online, supra note 12, at 103. ↑
- . Whitt, Hiding in the Open, supra note 12, at 69. ↑
- . Whitt, Old School Goes Online, supra note 12, at 103. See generally Amy Webb, The Big Nine: How the Tech Titans and Their Thinking Machines Could Warp Humanity (2019) (Webb includes the three Chinese companies in her pantheon of “tech titans” built on the Web platforms ecosystem model). ↑
- . Whitt, Hiding in the Open, supra note 12, at 74; see also Adam Thierer, The Internet of Things and Wearable Technology: Addressing Privacy and Security Concerns Without Derailing Innovation, 21 Rich. J. L. & Tech. 6, 12 (2015). ↑
- . Richard Whitt, Democratize AI (Part 1), Medium (Jun. 3, 2019), https://medium.com/swlh/democratize-ai-part-i-ade3cc7f727d [https://perma.cc/G8QA-NNP9] [hereinafter Whitt, Democratize AI (Part 1)]. ↑
- . Id. ↑
- . Id. ↑
- . Id. ↑
- . Id. ↑
- . See id. ↑
- . Id. ↑
- . Mark Weiser, The Computer for the 21st Century, Sci. Am. 94 (Sep. 1991), https://www.scientificamerican.com/article/the-computer-for-the-21st-century/ [https://perma.cc/ZK64-FEU5]. ↑
- . Nick Couldry & Andreas Hepp, The Mediated Construction of Reality 223 (2017). ↑
- . See William Lidwell, Kritina Holden & Jill Butler, Universal Principles of Design, at 92–93 (2003); Meadows, supra note 3, at 153–56. ↑
- . Javier Livas Cantu, What Is Cybernetics, Stafford Beer, Honoris Causa at Universidad de Valladolid, YouTube (Jun. 3, 2013), https://www.youtube.com/watch?v=uOj3Brkd_DE [https://perma.cc/Q4W3-VF4C]. ↑
- . See Amrit Tiwana, Platform Ecosystems: Aligning Architecture, Governance, and Strategy 207–10 (2014) (Interestingly, the SEAMs cycle correlates well to John Boyd’s concept of the “OODA” feedback loops developed by the U.S. military: Observe, Orient, Decide, and Act. Boyd’s insight is that competitive advantage comes from shortening the lag time between the four steps of collecting data, analyzing it, making a decision, and carrying it out. It would be intriguing to determine whether and how the online platform companies were influenced by United States military doctrine stemming from the Korean War). ↑
- . See Helen Nissenbaum, Privacy in Context 22 (2010) (In 2010, Helen Nissenbaum preferred to surveillance the phrase “monitoring and tracking.” She explained that the term surveillance suggests that those in power are monitoring people for purposes of modifying and controlling their behaviors. Some ten years later, the connotation actually fits rather well.). ↑
- . Zuboff, supra note 18, at 64; Whitt, Old School Goes Online, supra note 12, at 103 (This particular nomenclature draws from Hal Varian, Chief Economist at Google, who has used the phrase “data extraction and analysis” to describe some of what Web platforms do.). ↑
- . Whitt, Old School Goes Online, supra note 12, at 103. ↑
- . See Nissenbaum, supra note 44, at 22. ↑
- . Manipulate, Cambridge Cambridge Dictionary, https://dictionary.cambridge.org/us/dictionary/english/manipulate [https://perma.cc/8RGH-FGR9] (last visited Oct. 18, 2020). ↑
- . See generally Yochai Benkler, Robert Faris & Hal Roberts, Network Propaganda: Manipulation, Disinformation, and Radicalization in American Politics (2018). ↑
- . Id. ↑
- . Luciano Floridi, Marketing as Control of Human Interfaces and its Political Exploitation, 32 Phil. & Tech. 379, 383 (Aug. 10, 2019). ↑
- . Zuboff, supra note 18, at 186–87. ↑
- . Id. at 386. ↑
- . Arushi Jaiswal, Dark patterns in UX: how designers should be responsible for their actions, Medium (Apr. 15, 2018), https://uxdesign.cc/dark-patterns-in-ux-design-7009a83b233c [https://perma.cc/2S4Y-SPDH] (Jaiswal lists some eleven different misleading/deceptive UI/UX interfaces). ↑
- . See Zuboff, supra note 18, at 93–97 (the logic and operations of surveillance capitalism underlie “behavior futures markets.”); see also, Floridi, supra note 51, at 383 (The marketing imperative behind modern day computational systems “sees and uses people as interfaces.” These systems fail to respect their human dignity as persons, and disregard “what is ethically good for them intrinsically and individually.”). ↑
- . Zuboff, supra note 18, at 293. ↑
- . Id. ↑
- . Id. at 294–97. ↑
- . Id. at 294. ↑
- . Id. at 295. ↑
- . Id. at 295–96. ↑
- . Id. at 293. ↑
- . Id. at 507–12. ↑
- . Exec. Office of the President of the United States, Big Data and Differential Pricing 10 (Feb. 2015); id. at 16 (In 2015, the Obama Administration released a white paper detailing some of these practices. To the extent sellers may engage in the practice, “differential pricing could be conducive to fraud or scams that take advantage of unwary consumers.” It is unclear whether end users fully appreciate this practice.). ↑
- . Zuboff, supra note 18, at 307. ↑
- . Brett Frischmann & Evan Selinger, Re-engineering Humanity 270 (2018) [hereinafter Frischmann & Selinger, Re-Engineering Humanity]. ↑
- . Slavoj Zizek, Like a Thief in Broad Daylight: Power in the Era of Post-Humanity 42 (1st U.S. ed. 2019). ↑
- . See Wiliam James, The Principles of Psychology 561 (1890). ↑
- . Whitt, Old School Goes Online, supra note 12, at 115. ↑
- . See id. at 116–17. ↑
- . See id. at 117. ↑
- . Id. at 117 n.203. ↑
- . Whitt, Hiding in the Open, supra note 12, at 65. ↑
- . Id. ↑
- . Richard Whitt, A Deference to Protocol: Fashioning a Three-Dimensional Public Policy Framework for the Internet Age, 31 Cardozo Arts & Ent. 689, 746–47 (2013) [hereinafter Whitt, A Deference to Protocol]; Whitt, Hiding in the Open, supra note 12, at 65; see also Whitt, Old School Goes Online, supra note 12, at 116. ↑
- . See Whitt, Old School Goes Online, supra note 12, at 116. ↑
- . Catherine D’Ignazio & Lauren Klein, Data Feminism 60 (2020). ↑
- . Id. at 60–61. ↑
- . See, e.g., Kiran Bhageshipur, Data is the New Oil—And That’s A Good Thing, Forbes: Tech. Council (Nov. 15, 2019, 8:15 AM), https://www.forbes.com/sites/forbestechcouncil/2019/11/15/data-is-the-new-oil-and-thats-a-good-thing/#13627bb73045 [https://perma.cc/3PCP-VKPE] (data is “the new oil” has become a common refrain). ↑
- . Simon Sharwood, Scott McNealy: Your Data is Safer With Marketers Than Governments, The Register: Software (Mar. 14, 2017, 1:32 PM), https://www.theregister.com/2017/03/14/scott_mcnealy_on_privacy/ [https://perma.cc/8PND-S2MX]. ↑
- . Richard Esguerra, Google CEO Eric Schmidt Dismisses the Importance of Privacy, Electronic Frontier Found. (Dec. 10, 2009), https://www.eff.org/deeplinks/2009/12/google-ceo-eric-schmidt-dismisses-privacy [https://perma.cc/GA2V-R7G9]. ↑
- . Zuboff, supra note 18, at 293–97. ↑
- . Id. ↑
- . Id. ↑
- . See Martin Tisne, The Data Delusion: Protecting Individual Data Isn’t Enough When the Harm is Collective, Stan. Cyber Pol’y Ctr. 1, 2–4 (2020), https://cyber.fsi.stanford.edu/publication/data-delusion [https://perma.cc/U7VS-2GYU]. ↑
- . Id. at 5–6. ↑
- . Appendix B lays out a short “cheat sheet” that compares and contrasts these two approaches of computational accountability versus HAACS. ↑
- . See generally Maurice Merleau-Ponty, Phenomenology of Perception (1945); see generally Humberto Maturana & Francisco Varela, The Tree of Knowledge (1987). ↑
- . See, e.g., The Oxford Handbook of 4E Cognition (Albert Newen, Leon De Bruin & Shaun Gallagher, eds., 2018) (compendium of articles by leading neuroscience practitioners and philosophers). ↑
- . See generally Richard Ryan & Edward Deci, Self-Determination Theory (2017). ↑
- . See Fred Cummins, Agency is Distinct from Autonomy, 5.2 AVANT, 98 (2014). ↑
- . Id. at 107–08. ↑
- . Id. at 103. ↑
- . See also Jonardon Ganeri, The Self: Naturalism, Consciousness, and the First Person Stance, 252–55 (2013), (“[Autonomy] is the decision, a state of the self, that supervenes on a happening, a state of the body…”); Michael Luck & Mark d’Inverno, A Formal Framework for Agency and Autonomy, Proc. of the First Int’l Conf. on Multiagent Sys., 254, 258 (1995) (autonomy motivates agency). ↑
- . Frischmann & Selinger, Re-Engineering Humanity, supra note 66, at 225–302 (Free will defined as the “capability to engage in reflective self-determination about [one’s] will,” and autonomy as an intentional aspect of free will, serving as a “bridge between will and action.” Practical agency, then, is the freedom to exercise one’s will.) ↑
- . See generally Erich Fromm, Escape from Freedom (1974). ↑
- . Id. ↑
- . See Ryan & Deci, supra note 90, at 75–77. ↑
- . Joana Stella Kompa, Defining Human Autonomy: Towards an Interdependent Model of Human Agency, Digital Educ. & Soc. Change Blog (June 18, 2016) https://joanakompa.com/2016/06/18/defining-human-autonomy-in-search-of-richer-psychological-frameworks/ [https://perma.cc/4YSH-T26F]. ↑
- . Albert Camus, The Rebel: An Essay on Man in Revolt, 287–88 (1951). ↑
- . Roberto Unger, The Religion of the Future, 320 (2014) (deep freedom is “the dialectic between the conception of a free society, and the cumulative institutional innovations that will make this conception real”) [hereinafter Unger, The Religion of the Future]. ↑
- . Mark Taylor, The Moment of Complexity: Emerging Network Culture 224 (2001). See also Richard Whitt & Stephen Schultze, The New “Emergence Economics” of Innovation and Growth, and What it Means for Communications Policy, 7 J. Telecomm. & High Tech. L. 217, 309 (2009). ↑
- . Unger, The Religion of the Future, supra note 101, at 55 (“the transcendence of the self over its formative circumstances occurs in every department of human experience,” creating a “perpetual misfit between us and our situation.”). ↑
- . Couldry & Hepp, supra note 40, at 157. ↑
- . Valery Chirkov et al., Human Autonomy in Cross-Cultural Context: Perspectives on the Psychology of Agency, Freedom, and Well-Being 19–20 (2011). ↑
- . Cliff Kuang & Robert Fabricant, User Friendly: How the Hidden Rules of Design Are Changing the Way We Live, Work, and Play 33–34 (2019). ↑
- . Richard S. Whitt, Through A Glass Darkly, 33 Santa Clara High Tech. L.J. 117, 147–48 (2017) [hereinafter Whitt, Through A Glass Darkly]. ↑
- . Id. ↑
- . Id. ↑
- . Luciano Floridi, Information: A Very Short Introduction 42–43 (2010). ↑
- . See Whitt, Through A Glass Darkly, supra note 107, at 145–47 (The “noise/signal” duality is not mentioned directly by this piece; however, Whitt does make a relevant point. Information stored at the data level is bountiful and complex. Usable information comes from the abstract connection of those data points. Knowledge is the human understanding of the derived information and wisdom is found in the application of this knowledge. With each level up the hierarchy one goes, the noise is decreased and a usable signal precipitates.). ↑
- . Put more strongly in the vernacular of human rights, one can imagine asserting the right to define and utilize the mediation processes that help constitute one’s life. One also could assert the right to assign those definitional and use rights to third parties to provide assistance and support. ↑
- . Whitt, Hiding in the Open, supra note 12, at 76 (2018). ↑
- . Unger, The Religion of the Future, supra note 101, at 441 (Harv. U. Press ed. 2014). ↑
- . Roberto Unger, The Self Awakened: Pragmatism Unbound 166 (Harv. U. Press ed. 2007). ↑
- . Unger, The Religion of the Future, supra note 101, at 343. ↑
- . Id. at 180. ↑
- . See, e.g., Michael J. Spivery & Stephanie Huette, The Embodiment of Attention in the Perception-Action Loop, in The Routledge Handbook of Embodied Cognition 306 (Lawrence Shapiro ed., 2014). ↑
- . Couldry & Hepp, supra note 40, at 53. ↑
- . Peter-Paul Verbeek, Beyond Interaction: A Short Introduction to Mediation Theory, Interactions, at 31 (May–June 2015). ↑
- . Whitt, A Deference to Protocol, supra note 75, at 705 (paraphrasing David Clark). ↑
- . Whitt, Digital Stewardship, supra note 8, at 10–11. ↑
- . Whitt, A Deference to Protocol, supra note 75, at 707. ↑
- . Id. at 709–11. ↑
- . Id. ↑
- . Mikkel Flyverbom, The Digital Prism: Transparency and Managed Visibilities in a Datafied World 17, 47–49 (Cambridge U. Press, 2019). ↑
- . Id. ↑
- . Couldry & Hepp, supra note 40, at 1. ↑
- . Id. at 2. ↑
- . Id. at 223. ↑
- . Id. Nolan Gertz makes the disturbing point that, perhaps for many of us, digital technologies offer the ability to evade the burdens of consciousness, decision-making, powerlessness, individuality, and accountability. See generally Nolan Gertz, Nihilism and Technology (2000). Even if this theory holds true for some, the HAACS paradigm is intended for those who wish to at least consider embracing the “burdens” of being fully human, rather than sloughing them off on controlling corporate and political systems. ↑
- . See supra Part I.C. (for discussion on asymmetrical interfaces). ↑
- . See Frischmann & Selinger, Re-engineering Humanity, supra note 66, at 261–66. ↑
- . Ryan & Deci, supra note 90, at 51–79, 383–92 (describes the development of one’s personal identities through both the self-as-process and the self-as-object prisms). ↑
- . Cummins, supra note 91. ↑
- . Jaak Panksepp & Lucy Biven, The Archaeology of the Mind: Neuroevolutionary Origins of Human Emotions 497 (2012). ↑
- . Valery I. Chirkov et al., Human Autonomy in Cross-Cultural Context, Cross-Cultural Advancements in Positive Psychology 1 (2011). ↑
- . See generally Shawn Gallagher, Phenomennology and Embodied Cognition, in The Routledge Handbook of Embodied Cognition 9, 9–17 (Lawrence Shapiro ed., 2014). ↑
- . Nick Couldry & Ulises A. Mejias, The Costs of Connection: How Data is Colonizing Human Life and Appropriates It for Capitalism 161 (2019). ↑
- . Id. at 156. ↑
- . Maria Brincker, Privacy in public and the contextual conditions of agency, in Privacy in Public Space: Regulatory and Legal Challenges 84, 85 (Tjerk Timan, Bryce Clayton Newell & Bert-Jaap Koops eds., 2017). ↑
- . See generally Albert Newen et al., The Oxford Handbook of 4E Cognition (2018). ↑
- . See Nesta Devine & Ruth Irwin, Autonomy, Agency and Education, 37 Educ. Philos. Theory 317, 320–28 (June 2005) (the Enlightenment era edifice crumbles of the fully rational and autonomous self). ↑
- . Kompa, supra note 99, at 4. ↑
- . See Meadows, supra note 3, at 153–57. ↑
- . Apologies to some traditionalists for employing here the plural rather than the singular form (datum). ↑
- . Daniel Rosenberg, Data Before the Fact, in “Raw Data” Is an Oxymoron (2013), 15, at 36–37. See also D’Ignazio & Klein, supra note 77, at 10 (the word “data” was introduced in the mid-seventeenth century to supplement pre-existing terms such as “evidence” and “fact”). ↑
- . Geoffrey C. Bowker, Foreword to Yanni Alexander Loukissas, All Data Are Local: Thinking Critically in a Data-Driven Society, at ix (2019). ↑
- . See Whitt, Hiding in the Open, supra note 12, at 66–70. ↑
- . See generally Whitt, Through a Glass Darkly, supra note 107. ↑
- . Id. at 188–92 (information lifecycles and systems layers models can support long-term digital preservation proposals). ↑
- . See Whitt, Old School Goes Online, supra note 12, at 103–05. ↑
- . Analog, TechTerms, https://techterms.com/definition/analog [https://perma.cc/D3NT-C4BU] (last updated Sept. 12, 2018). ↑
- . Id. ↑
- . See Bert-Jaap Koops et al., A Typology of Privacy, 38 U. Pa. J. Int’l L. 483 (2017) (describing eight types of personal privacy that align with different data types). ↑
- . D’Ignazio & Klein, supra note 77, at 10. ↑
- . See Whitt, Through a Glass Darkly, supra note 107, at 145–47 (providing an overview of the long-debated data-information-knowledge-wisdom (“DIKW”) hierarchy). ↑
- . David J. Hand, Dark Data: Why What You Don’t Know Matters 11–12 (2020) (“[E]xamples of this second kind, in which we don’t know that something is missing, are ubiquitous. . . . As you will see, dark data have many forms. Unless we are aware that data might be incomplete, . . . we could get a very misleading impression of what’s going on.”). ↑
- . Couldry & Hepp, supra note 40, at 124–25. ↑
- . D’Ignazio & Klein, supra note 77, at 12. ↑
- . Couldry & Hepp, supra note 40, at 124–25. ↑
- . Brincker, supra note 141, at 65. ↑
- . Zuboff, supra note 18, at 93–97, 293–97. ↑
- . See Biometrics: Definition, Trends, Use Cases, Laws, and Latest News, Thales Group, https://www.thalesgroup.com/en/markets/digital-identity-and-security/government/inspired/biometrics [https://perma.cc/U9KU-27SZ] (last updated Sept. 10, 2020). ↑
- . See Behavioral Biometrics, Int’l Biometrics & Identity Ass’n, https://www.ibia.org/download/datasets/3839/Behavioral%20Biometrics%20white%20paper.pdf [https://perma.cc/5Q3A-Z458] (last visited Oct. 18, 2020). ↑
- . See Koops et al., supra note 155, at 560–62. ↑
- . Empathy 2.0 Series: How Biometrics Can Help You Understand Your Customers, Bd. Innovation,https://www.boardofinnovation.com/blog/how-biometrics-can-help-you-understand-your-customers/ [https://perma.cc/MBK8-Q8JR] (last visited Oct. 18, 2020). ↑
- . Id. ↑
- . Daisuke Wakabayashi & Alistair Barr, Apple and Google Know What You Want Before You Do, Wall St. J. (Aug. 3, 2015, 2:14 PM), https://www.wsj.com/articles/apple-and-google-know-what-you-want-before-you-do-1438625660 [https://perma.cc/4LDC-QNSS]. ↑
- . Stephen T. Asma & Rami Gabriel, The Emotional Mind: The Affective Roots of Culture and Cognition 25, 27 (2019). ↑
- . Yanni Alexander Loukissas, All Data Are Local: Thinking Critically in a Data-Driven Society 196 (2019). ↑
- . “Lifestreaming” was coined in the mid-2000s to describe the process of documenting and sharing outputs of one’s social experiences. Lifestreaming, WikiVisually, https://wikivisually.com/wiki/Lifestreaming [https://perma.cc/JS4X-X9FF] (last visited Oct. 18, 2020). Steve Rubel, an early enthusiast, likened lifestreaming to the digital equivalent of Leonardo da Vinci’s notebooks—his recorded notes, drawings, questions, and more. Id. In HAACS parlance, these products are indicia of one’s agency in the world. A more intriguing angle is to utilize digital technology to tap into the raw material of the autonomous self. ↑
- . As D’Ignazio and Klein recently asked, “how can we use data to remake the world?” D’Ignazio & Klein, supra note 77, at 5. The authors advocate using data science to challenge and change existing distributions of power, particularly where dimensions of individual and group identity intersect with each other to determine one’s experiences in the world. Id. at 4–8. ↑
- . See infra Part V. ↑
- . Brincker, supra note 141, at 85. ↑
- . See, e.g., Rethinking Data, Ada Lovelace Inst. (2020), https://www.adalovelaceinstitute.org/wp-content/uploads/2020/01/Rethinking-Data-Prospectus-Print-Ada-Lovelace-Institute-2019.pdf [https://perma.cc/AH3K-PUSA]. ↑
- . Aashish Aryan, Explained: What is Non-Personal Data, IndianExpress (July 27, 2020, 5:20 AM), https://indianexpress.com/article/explained/non-personal-data-explained-6506613/ [https://perma.cc/ZF65-LMTD]. ↑
- . Nick Srnicek, Platform Capitalism 40 (2017). ↑
- . Id. ↑
- . Using the phraseology of the SEAM cycle also is an attempt to capture that connotation of a dirty resource—in this case, “seams” of coal. ↑
- . Nils Gilman & Maya Indira Ganesh, Making Sense of the Unknown, in AI +1: Shaping Our Integrated Future 74, 77 (2020). ↑
- . Data Exhaust, Techopedia, https://www.techopedia.com/definition/30319/data-exhaust [https://perma.cc/6BJT-5E98] (last visited Oct. 18, 2020). ↑
- . See, e.g. Jarod Lanier, Who Owns the Future (2013) (stating that users should be paid for their data). ↑
- . With regard to the proposal that users should share in monetizing their personal data, Elizabeth Renieris points out some practical challenges. These include that the user will (1) lack transparency in how the data ultimately will be used, (2) not have her “own” data to sell, and (3) bring little bargaining power to the transactions. Propertizing data also discriminates against the disadvantaged. Jeff Benson, Harvard’s Elizabeth Renieris: Privacy Is an Inalienable Right, Digital Privacy News (Mar. 31, 2020), https://digitalprivacy.news/2020/03/31/harvards-elizabeth-renieris-privacy-is-an-inalienable-right/ [https://perma.cc/BGH6-JZMH]. ↑
- . See Doc Searls, We Can Do Better Than Selling Our Data, Doc Searls Weblog (Sept. 18, 2018), https://blogs.harvard.edu/doc/2018/09/18/data/ [https://perma.cc/59LY-AERK]; Elizabeth Renieris et al., You Really Don’t Want to Sell Your Data, Slate (April 7, 2020, 10:00 AM), https://slate.com/technology/2020/04/sell-your-own-data-bad-idea.html [https://perma.cc/4XFX-JMRX]. ↑
- . Are Data More Like Oil or Sunlight?, Economist (Feb. 20, 2020), https://www.economist.com/special-report/2020/02/20/are-data-more-like-oil-or-sunlight [https://perma.cc/ZET2-GNTA]. ↑
- . See supra Part I.D. ↑
- . See supra Part I.D. ↑
- . See supra Part I.D. ↑
- . One important caveat: what follows assumes that “data” fits within conventional analyses of economic goods. Given the somewhat unique nature of data, conceptualized as digital flows of heterogenous, relational, and contextual lifestreams, many of the traditional answers may not provide an optimal fit. Much research and scholarship remain ahead. ↑
- . Factors of Production: The Economic Lowdown Podcast Series, Episode 2, Fed. Res. Bank St. Louis, https://www.stlouisfed.org/education/economic-lowdown-podcast-series/episode-2-factors-of-production [https://perma.cc/68WB-YPT5] (last visited Oct. 18, 2020). ↑
- . For example, some economists believe that data should be seen as a form of human labor. See, e.g., Imanol Arrieta-Ibarra et al., Should We Treat Data as Labor? Moving Beyond “Free”, 108 Am. Econ. Ass’n 38 (2018) (data as labor offers a radical opportunity to shape new digital markets). ↑
- . Brett M. Frischmann, Infrastructure: The Social Value of Shared Resources 24–30 (2012) [hereinafter, Frischmann, Infrastructure: The Social Value of Shared Resources]. ↑
- . Id. at 25. ↑
- . Id. at 27. ↑
- . Data’s Identity in Today’s Economy, MIT Tech. Rev. (Apr. 7, 2016), https://www.technologyreview.com/2016/04/07/108767/datas-identity-in-todays-economy/ [https://perma.cc/YX4J-ZEG8]. ↑
- . Id. ↑
- . Frischmann, Infrastructure: The Social Value of Shared Resources, supra note 193, at 25. ↑
- . Id. ↑
- . Id. at 39. ↑
- . Id. at 32. ↑
- . Id. at 38. ↑
- . See Richard Whitt, Adaptive Policymaking: Evolving and Applying Emergent Solutions for U.S. Communications Policy, 61 Fed. Comm. L.J. 483, 512–26 (2009) [hereinafter Whitt, Adaptive Policymaking]. ↑
- . Frischmann, Infrastructure: The Social Value of Shared Resources, supra note 193, at 26–33. ↑
- . See Whitt, Adaptive Policymaking, supra note 203, at 522–23. ↑
- . Frischmann, Infrastructure: The Social Value of Shared Resources, supra note 193, at 34. As Frischmann points out, “Nonrival resources provide an additional degree of freedom, with respect to resource management.” Id. at 30. Non-rivalry for a naturally shareable good can be leveraged to support a wider range of choices, including allocating its possession and use on a nonexclusive basis. Id. On the other hand, exclusivity is also a potentially attractive tool for managing risks that the good will be misappropriated. Id. at 33. ↑
- . Yuliya Panfil & Andrew Hagopian, A Commons Approach to Data Governance, New Am. (Sept. 5, 2019), https://www.newamerica.org/weekly/edition-260/commons-approach-to-data-governance/ [https://perma.cc/F7QR-ZSEY]. ↑
- . Frischmann, Infrastructure: The Social Value of Shared Resources, supra note 193, at 8. ↑
- . Whitt, A Deference to Protocol, supra note 75, at 747–48. ↑
- . Id. at 747. ↑
- . See Frischmann, Infrastructure: The Social Value of Shared Resources, supra note 193, at 253–314. Closely related to the concept of “data” is “ideas.” New growth economist Paul Romer found ideas to be both non-rivalrous (readily shared for re-use) and at least partially excludable (sharing can be limited). See Richard Whitt & Stephen Schultze, The New ‘Emergence Economic’ of Innovation and Growth, and What It Means for Communications Policy, 7 J. Telecomm. & High Tech. L. 217, 264–67 (2009). ↑
- . Frischmann, Infrastructure: The Social Value of Shared Resources, supra note 193, at 253. ↑
- . Id. at 254. ↑
- . Charlotte Hess, The Unfolding of the Knowledge Commons, 8 St. Anthony’s Int’l R. 13, 20–21 (2012). ↑
- . The history of the commons, and subsequent enclosures by political and commercial interests, may provide a suitable framing for ongoing debates about treating as private property (or “enclosing”) data. See, e.g., Peter Linebaugh, Enclosures from the Bottom Up, in The Wealth of the Commons: A World Beyond Market & State 114–24 (David Bollier & Silke Helfrich eds., 2012) (explores opposition to various market enclosures of shared resources, and the generative power of the commons). To some, data may represent the ultimate—last?—global enclosure opportunity, beyond the land and labor resources of the past. ↑
- . See generally Zuboff, supra note 18. ↑
- . Nassim Nicholas Taleb, Skin in the Game: Hidden Asymmetries in Daily Life 154 (2018). ↑
- . For a deeper exploration of fiduciary law in the context of the digital world, see generally Whitt, Old School Goes Online, supra note 12. ↑
- . Id. at 86. ↑
- . Tamar Frankel, Fiduciary Law 79 (2010). ↑
- . See generally The Oxford Handbook of Fiduciary Duties (Evan J. Criddle et al. eds., 2019). ↑
- . Id. at 471–663. ↑
- . Whitt, Old School Goes Online, supra note 12, at 86. ↑
- . Frankel, supra note 220, at 6. ↑
- . Whitt, Old School Goes Online, supra note 12, at 87. ↑
- . Id. at 88. ↑
- . Id. at 89. ↑
- . Id. at 88. ↑
- . Id. at 86. ↑
- . Id. at 88. ↑
- . Id. ↑
- . Id. at 91. ↑
- . Id. ↑
- . Id.; other fiduciary duties include good faith and confidentiality. Fiduciary Duties, Black’s Law Dictionary (11th ed. 2019) (defining other fiduciary duties as “. . .good faith, trust, special confidence, and candor…”). ↑
- . Whitt, Old School Goes Online, supra note 12, at 89. ↑
- . Id. ↑
- . Id. ↑
- . Id. ↑
- . Id. at 87. ↑
- . Id. at 129. ↑
- . See Elizabeth Renieris & Dazza Greenwood, Do we really want to ‘sell’ ourselves? The risks of a property law paradigm for personal data ownership, Medium (Sept. 23, 2018), https://medium.com/@hackylawyER/do-we-really-want-to-sell-ourselves-the-risks-of-a-property-law-paradigm-for-data-ownership-b217e42edffa [https://perma.cc/Y6FX-3J4R] (arguing for inclusion of constitutional or human rights laws in the framing for our identity-related data). ↑
- . See supra Part II. ↑
- . See generally Human Rights and the US, The Advoc. for Hum. Rts., http://www.theadvocatesforhumanrights.org/human_rights_and_the_united_states [https://perma.cc/2XGT-AKVH] (last visited Oct. 18, 2020). ↑
- . See Fiduciary Government 1 (Evan J. Criddle et al. eds., 2018). ↑
- . Whitt, Hiding in the Open, supra note 12, at 86; see generally id. ↑
- . See generally Fiduciary Government, supra note 244. ↑
- . Gary Lawson & Guy Seidman, A Great Power of Attorney: Understanding the Fiduciary Constitution 4 (2017); see also James R. Stoner, Jr. Common-Law Liberty 10 (2003) (making the case for the US Constitution’s grounding in the common law). ↑
- . Lawson & Seidman, supra note 247, at 172. ↑
- . See Evan J. Criddle & Evan Fox-Decent, Fiduciaries of Humanity: How International Law Constitutes Authority 85–94 (Oxford U. Press, 2016) (writing that leading theories struggle to offer persuasive support for the basis, content, and scope of human rights). ↑
- . Whitt, Old School Goes Online, supra note 12, at 86. ↑
- . Criddle & Fox, supra note 249, at 94. ↑
- 252. Id. ↑
- . See Whitt, Old School Goes Online, supra note 12, at 128–30, for a discussion on common law doctrine that may be worth investigating as well, as part of fashioning a broad-based “digital common law” for the 21st Century. Examples include the law of “information torts,” misappropriation, and bailment. ↑
- . See generally Meadows, supra note 3, at 145–66 (discussing ways people can intervene to restructure the systems we live in, identifying leverage points for change). ↑
- . See Richard Whitt, Human Agency in the Digital Era, Not Simple (Jan. 8, 2020), http://notsimple.libsyn.com/richard-whitt-human-agency-in-the-digital-era [https://perma.cc/R4KB-LDAV]; Singularity University, What if the Internet Was Safe? Richard Whitt & Doc Searls, YouTube (Dec. 3, 2019), https://www.youtube.com/watch?v=NyQFbu5SUYo [https://perma.cc/FYD4-4JZ4]; Richard Whitt, To fix the web, give it back to users, Fast Company (Jan. 22, 2019), https://www.fastcompany.com/90293980/to-fix-the-web-give-it-back-to-the-users [https://perma.cc/GRL8-L37V]. ↑
- . See GLIA.net, www.glia.net/about [https://perma.cc/3QD5-YNSG] (last visited Oct. 18, 2020). ↑
- . See Stephen R. Covey (@StephenRCovey), Twitter (Mar. 18, 2020, 7:01 AM), https://twitter.com/stephenrcovey/status/1240277058082811904?lang=en [https://perma.cc/J3JR-8V5G]; relatedly, “glia” (as in the GLIAnet project) is the ancient Greek work for glue. ↑
- . See, e.g., Eric M. Uslaner, The Study of Trust, The Oxford Handbook of Social and Political Trust (Eric M. Uslaner ed., 2018) (writing that levels of trust in other people and institutions seems lower today than in the past); 2020 Edelman Trust Barometer, Edelman (Jan. 19, 2020), https://www.edelman.com/trustbarometer?te=1&nl=the-interpreter&emc=edit_int_20200228&campaign_id=30&instance_id=16345&segment_id=21717&user_id=809a67bf3380d4e9e018934dc88fe3ac®i_id=8282764120200228 [https://perma.cc/MJW9-2KPV] (showing that none of the four societal institutions of government, business, NGOs, and media are well trusted). ↑
- . Rachel Botsman, Who Can You Trust? How Technology Brought Us Together and Why It Might Drive Us Apart 7–9 (2017). ↑
- . Id. at 28. ↑
- . Id. ↑
- . Id. ↑
- . Id. at 262. ↑
- . Id. at 40–41. ↑
- . Id. at 50–51, 257–60. ↑
- . Id. at 50–51. ↑
- . Id. at 262–63. ↑
- . Id. at 148. ↑
- . One root cause for this declining lack of trust could be the nature of the American corporation, and its embrace of the paradigm of so-called “shareholder” capitalism. To some, the recent advent of stakeholder capitalism means a broadening of the ends to which these corporations will strive, including serving the needs of customers, employees, and even society at large. See Peter Corning, Shareholder Capitalism vs. Stakeholder Capitalism, Institute for the Study of Complex Systems (Sept. 17, 2019), https://complexsystems.org/576/shareholder-capitalism-vs-stakeholder-capitalism/ [https://perma.cc/94R9-3MCR]. ↑
- . Botsman, supra note 259, at 8–9, 259–60. ↑
- . See generally Richard Whitt, A Human-Centered Paradigm for the Web, John Snow: First Health Data Trust, Medium (Sept. 21, 2020) https://whitt.medium.com/a-human-centered-paradigm-for-the-web-27ae40159778 [https://perma.cc/5BDU-GT4S] (discusses the online paradigm of SEAMs, and advances a counter-paradigm of enhancing human autonomy; suggests creating effective leverage points that include more human-centric infrastructures). ↑
- . Taleb, supra note 217. ↑
- . Botsman, supra note 259, at 108. ↑
- . Id. at 7–9. ↑
- . Whitt, Digital Stewardship, supra note 8, at 13–16. ↑
- . Whitt, Old School Goes Online, supra note 12, at 102–09 ↑
- . Id. at 106–09. ↑
- . Id. at 114–15. (Using here the term “client” denotes both this new fiduciary relationship with trusted agents, and the client-server networking relationship colloquially at the heart of the World Wide Web. Addressing the online power asymmetries plaguing users also means righting the network imbalance between servers that should (only) be serving, and clients that should (actually) be in charge). ↑
- . See Sylvie Delacroix & Neil D. Lawrence, Bottom-Up Data Trusts: Disturbing the ‘One Size Fits All” Approach to Data Governance, 9 Int’l Data Privacy L. 236 (2019), https://academic.oup.com/idpl/article/9/4/236/5579842 [https://perma.cc/4EN3-6WEM]. ↑
- . See Whitt, Old School Goes Online, supra note 12, at 126; see id. ↑
- . See Whitt, A Human-Centered Paradigm for the Web, supra note 271. ↑
- . See Richard Whitt, From Thurii to Quayside: Creating Inclusive Blended Spaces in Digital Communities, (Oct. 4, 2020) (unpublished manuscript) https://papers.ssrn.com/abstract=3709111 [https://perma.cc/F34G-6PTM]. ↑
- . Whitt, Old School Goes Online, supra note 12, at 110–13. ↑
- . See id. at 119 (discusses the digital fiduciary model, a feature of the GLIAnet Project). ↑
- . A salient question is whether/how corporations organized under either the “shareholder” or “stakeholder” forms of modern capitalism would successfully fit within the HAACS paradigm. The Author also has posited that incumbent platform companies should be barred from serving as digital fiduciaries, unless and until they significantly change their existing business models. See generally id. at 120–21. ↑
- . See Whitt, A Human-Centered Paradigm for the Web, supra note 271. ↑
- . Whitt, Old School Goes Online, supra note 12, at 119. ↑
- . Zuboff, supra note 18, at 93–97. ↑
- . Jesse Frederik & Maurits Martijn, The New Dot Com Bubble is Here: It’s Called Online Advertising, The Correspondent (Nov. 6, 2019), https://thecorrespondent.com/100/the-new-dot-com-bubble-is-here-its-called-online-advertising/13228924500-22d5fd24/ [https://perma.cc/CT3H-VZFT]. ↑
- . See, e.g., Richard Whitt & Milton Pedraza, Luxury Institute and GLIA Foundation: Empowering Personal Data For Exponential Economic Growth, GlobalNewswire (Apr. 7, 2020), https://www.globenewswire.com/fr/news-release/2020/04/07/2012776/0/en/Luxury-Institute-and-GLIA-Foundation-Empowering-Personal-Data-For-Exponential-Economic-Growth.html [https://perma.cc/97WY-XUWY] (making the case for luxury brands to provide personalized services to clients as digital fiduciaries). ↑
- . Whitt, Old School Goes Online, supra note 12, at 119. ↑
- . See also Richard Whitt, A Human-Centered Paradigm for the Web, Digital Fiduciaries plus Personal AIs, Medium (Aug. 17, 2020), https://whitt.medium.com/a-human-centered-paradigm-for-the-web-e7ceaee8fb0e [https://perma.cc/RBU7-SH5E]. ↑
- . See infra Part V.C.1. ↑
- . Whitt, Old School Goes Online, supra note 12, at 107. ↑
- . Id. ↑
- . Id. ↑
- . Id. ↑
- . Id. ↑
- . Id. ↑
- . Id. ↑
- . Id. ↑
- . Id. ↑
- . See id. ↑
- . See supra Part III.B.2. ↑
- . Whitt, A Deference to Protocol, supra note 75, at 709–14. ↑
- . Id. at 717–29. ↑
- . See supra Part I.A. See also Whitt, Hiding in the Open, supra note 12, at 68–70; Whitt, Old School Goes Online, supra note 12, at 102–05. ↑
- . See Whitt, Hiding in the Open, supra note 12, at 68–70. ↑
- . This proposed e2a design principle has some parallels to the concept of the peer-to-peer (“p2p”) relationship. See Rudiger Schollmeier, A Definition of Peer-to-Peer Networking for the Classification of Peer-to-Peer Architectures and Applications (Sep. 2001), https://www.it.lut.fi/wiki/lib/exe/fetch.php/courses/ct30a6900/p2pdefinitions.pdf [https://perma.cc/5PDL-78FP] (providing a clear definition of peer-to-peer networking). The e2a nomenclature, rather than p2p, is employed here for two reasons. First, the proposed design principle is intended to supplement, not replace, the existing Web architecture. Second, as a technical matter, “edge” users should directly control their interactions with all other entities residing on the Web, not just with other “edge” users acting as nominal peers. ↑
- . See Pedro Domingos, The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World 1 (2015). ↑
- . Id. at 13–16. ↑
- . See supra Part I.B. ↑
- . For a more in-depth analysis, see Richard Whitt, A Web That Weaves Itself: Foundational Dimensions of the New Machine Intelligence Era 63–75 (unpublished manuscript) (on file with Author). ↑
- . Id. ↑
- . Id. ↑
- . Id. ↑
- . Id. ↑
- . Id. ↑
- . See Frischmann & Selinger, Re-Engineering Humanity, supra note 66, at 184–208. ↑
- . A more in-depth discussion of the practical case for Personal AIs can be found in the Author’s three-part Medium series, posted online as a single white paper. Richard Whitt, Democratizing AI: Ensuring human autonomy over our computational “screens, scenes, and unseens,” (July 31, 2019), https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3669909 [https://perma.cc/96UX-E72K]. ↑
- . Id. ↑
- . Of course, potentially melding the Human and the AI raises profound questions. The “Becoming Human” community has an intriguing site to address some such questions. Medium: Becoming Human, https://becominghuman.ai/ [https://perma.cc/4VX7-GXH8] (last visited Oct. 18, 2020). ↑
- . Whitt, Democratizing AI, supra note 320. ↑
- . E-mail from Todd Kelsey, Assoc. Professor, Benedictine University to author (on file with author). ↑
- . Whitt, Democratizing AI, supra note 320. ↑
- . E-mail from Todd Kelsey, Assoc. Professor, Benedictine University to author (on file with author). ↑
- . IEEE, Ethically Aligned Design: General Principles 23, https://standards.ieee.org/content/dam/ieee-standards/standards/web/documents/other/ead1e_general_principles.pdf [https://perma.cc/3SSA-68UH] (last visited, Oct. 18, 2020). ↑
- . Id. at 24. ↑
- . IEEE, Ethically Aligned Design: Personal Data and Individual Agency 113–14, https://standards.ieee.org/content/dam/ieee-standards/standards/web/documents/other/ead1e_personal_data.pdf [https://perma.cc/RH35-ZEKM] (last visited, Oct. 18, 2020). ↑
- . Id. at 114. ↑
- . Id. ↑
- . Standard for Personal Data Artificial Intelligence (AI) Agent, IEEE Standards Association https://rc-ras-stg.ieee.org/content/ieee-standards/en/project/7006.html [https://perma.cc/UB8S-K3C5] (last visited Oct. 4, 2020). ↑
- . See supra Part I.C. ↑
- . See supra Part III.B.1. ↑
- . Kuang & Fabricant, supra note 106, at 32. ↑
- . Id. at 34. ↑
- . Alexander R. Galloway, The Interface Effect 120–21 (2012). ↑
- . Id. at 31. ↑
- . Id. at 30–31. ↑
- . Couldry & Hepp, supra note 40, 48–52, 221–23 (2016). ↑
- . Galloway, supra note 337, at 90–94. ↑
- . Kuang & Fabricant, supra note 106, at 145. ↑
- . Floridi has dubbed Janus the two-faced “god of interfaces,” because he is by definition bifront: to the user, and to the prompter. While prompters controlling the terms of interfaces is troubling enough, Floridi sees real danger when both faces of Janus are hidden, in technologies that only talk to one another, rather than to us. Luciano Floridi, The Fourth Revolution 34–36 (2014). ↑
- . See Whitt, Old School Goes Online, supra note 12, at 121. ↑
- . About Opal, Opal, https://www.opalproject.org/about-opal [https://perma.cc/YF4C-XHRP] (last visited Nov. 3, 2020). One company moving forward with a business model premised on OPAL’s edge-pull functionality is FortifID. The company’s website indicates that its platform is “designed to reduce the raw data footprint across a company’s ecosystem,” because the “algorithms travel to the data and produce insights that are shipped back for use instead of raw data.” https://www.fortifid.com/ [https://perma.cc/2WSY-LRLU]. ↑
- . See generally Project VRM, Harvard, https://cyber.harvard.edu/projectvrm/Main_Page [https://perma.cc/K69P-XDT6 ] (last visited Nov. 3, 2020); Doc Sears, Berkman Klein Ctr. for Internet & Soc’y at Harv. U., https://cyber.harvard.edu/people/dsearls [https://perma.cc/F2L7-359E] (last visited Nov. 3, 2020). ↑
- . Doc Searls, Personal Agency Matters More than Personal Data, ProjectVRM (June 23, 2018), https://blogs.harvard.edu/vrm/2018/06/23/matters/ [https://perma.cc/4QJT-S4QG]. ↑
- . Id. ↑
- . See William Lidwell, Kritina Holden & Jill Butler, Universal Principles of Design 94 (2003). ↑
- . See Searls, supra note 347. ↑
- . Whitt, Old School Goes Online, supra note 12, at 123–24, 126; Whitt, Hiding in the Open, supra note 12, at 53–54. ↑
- . Whitt, Hiding in the Open, supra note 12, at 42–45. ↑
- . Many of these “functional openness” concepts—such as network interconnection, service interoperability, and resource portability—are rooted in regulatory policies developed in the 1980s and 1990s by the U.S. Federal Communications Commission (FCC) and other national regulators, as a way to facilitate competitive communications services markets. See id. at 45–65. ↑
- . Whitt, Old School Goes Online, supra note 12, at 123–24. ↑
- . Id. ↑
- . Id. at 123–24, 126. ↑
- . Id.; Press Release, Sen. Mark Warner, Senators Introduce Bipartisan Bill to Encourage Competition in Social Media, (Oct. 22, 2019), https://www.warner.senate.gov/public/index.cfm/2019/10/senators-introduce-bipartisan-bill-to-encourage-competition-in-social-media [https://perma.cc/R57L-CPJK]. ↑
- . See generally Self-driving car, Wikipedia, https://en.wikipedia.org/wiki/Self-driving_car [https://perma.cc/44XS-DF8D] (last visited Oct. 4, 2020) The term “autonomous vehicles” is interesting—by definition, some autonomy/agency is removed from the driver. One question is, to what end? ↑
- . Whitt, Democratize AI (Part 1), supra note 32 (other current examples include “smart” doorbells scanning other people’s homes, drones hovering outside bedroom windows, and facial recognition cameras scanning local bars). ↑
- . See Sidewalk Labs, https://www.sidewalktoronto.ca/plans/quayside [https://perma.cc/LF2C-4W9V] (last visited Oct. 18, 2020). ↑
- . Id. ↑
- . For two informed perspectives on the history of the Sidewalk Labs saga in Toronto, see Anna Artyushina, Is Civic Data Governance the Key to Democratic Smart Cities? The Role Of The Urban Data Trust In Sidewalk Toronto, Telematics and Informatics (July 6, 2020), at 6–10, https://www.sciencedirect.com/science/article/abs/pii/S0736585320301155 [https://perma.cc/G7X8-AMU9]; Teresa Scassa, Designing Data Governance for Data Sharing: Lessons from Sidewalk Toronto, Technology and Regulation, Tech. & Reg. (July 16, 2020), https://techreg.org/index.php/techreg/article/view/51 [https://perma.cc/ERU3-CQGL]. ↑
- . Isabelle Kirkwood, Sidewalk Labs Announces It Will “No Longer Pursue” Quayside Project, Betakit (May 7, 2020), https://betakit.com/sidewalk-labs-announces-it-will-no-longer-pursue-quayside-project/#:~:text=Sidewalk%20Labs%20announces%20it%20will%20”no%20longer%20pursue”%20Quayside%20project,will%20both%20remain%20in%20Toronto [https://perma.cc/GXA8-B569]. ↑
- . For further details on these two takeaways from the Toronto project, see Whitt, From Thurii to Quayside: Creating Inclusive Blended Spaces in Digital Communities, supra note 282. See also Richard Whitt, From Thurii to Quayside: Creating Inclusive Digital Communities, Medium (Oct. 22, 2020), https://whitt.medium.com/from-thurii-to-quayside-creating-inclusive-digital-communities-348cde93215f [https://perma.cc/M2Y8-8KZZ]. ↑
- . See Designing for Digital Transparency in the Public Realm, Sidewalk Labs https://www.sidewalklabs.com/dtpr/ [https://perma.cc/ZPA5-TS2F] (last visited Oct. 18, 2020). ↑
- . Advancing Digital Transparency in the Public Realm, Sidewalk Labs, https://process.dtpr.dev/ [https://perma.cc/ZYX2-FHW4] (last visited Oct. 18, 2020). ↑
- . Id. ↑
- . Charette #3, Sidewalk Labs, https://process.dtpr.dev/blog/third-and-last-charrette [https://perma.cc/9CJB-F5LC] (last visited Oct. 18, 2020). ↑
- . Research Session 3: Exploring the Potential of Trusted Digital Assistants, Sidewalk Labs, https://process.dtpr.dev/blog/research-session-3-exploring-the-potential-of-trusted-digital-assistants [https://perma.cc/PS89-R3K2] (last visited Oct. 18, 2020). ↑
- . About, DTPR, https://dtpr.helpfulplaces.com/ [https://perma.cc/4DEZ-USH3] (last visited Nov. 3, 2020). ↑
- . Id. The project even has a five-year vision for increasing accountability and enabling new forms of personal agency in digital communities. Id. ↑
- . Scassa, supra note 362, at 54–55. ↑
- . Id. at 54–56. ↑
- . Donovan Vincent, Sidewalk Labs’ Urban Data Trust is Problematic,’ Says Ontario Privacy Commissioner, The Star (Sept. 26, 2019), https://www.thestar.com/news/gta/2019/09/26/sidewalk-labs-urban-data-trust-is-problematic-says-ontario-privacy-commissioner.html [https://perma.cc/VCL9-KWEL]. ↑
- . Scassa, supra note 362, at 56. See also Artyushina, supra note 362, at 6–10. ↑
- . See generally, Glia.net, https://www.glia.net/glianet-project [https://perma.cc/339Q-BVFM] (last visited Oct. 18, 2020) (Obfuscating tech tools are another way for the autonomous agent to protect and promote her interests); See Finn Brunton & Helen Nissenbaum, Obfuscation: A User’s Guide for Privacy and Protest 8–41 (report. 2016) (2015) (In the smart city environment, for example, trusted entities can arm their clients with anti-surveillance gear to disrupt and “obfuscate” how sensors attempt to track/trick/hack them via SEAM cycles operating behind the “scenes.”). ↑
- . Whitt, Through A Glass Darkly, supra note 111, at 126. ↑
- . Rebecca Solnit, A Paradise Built in Hell 313 (2010). ↑
- . See Whitt, Old School Goes Online, supra note 12, at 123-124. ↑
- . See Almond: The Open, Privacy Preserving Virtual Assistant, Stan. Open Virtual Assistant Lab https://almond.stanford.edu, [https://perma.cc/4BRX-JGPJ] (last visited Oct. 18, 2020). ↑
- . See generally, e.g., Edge Computing Reference Architecture 2.0, Edge Computing Consortium & All. of Indus. Internet (2017). ↑
- . See, e.g., Robert Hof, No cloud required: Why AI’s future is at the edge, siliconANGLE (May 16, 2019 4:52 PM), https://siliconangle.com/2019/05/26/no-cloud-required-ais-future-edge/ [https://perma.cc/Q4LF-4U8Q]. ↑
- . See, e.g., Brendan McMahan & Daniel Ramage, Federated Learning: Collaborative Machine Learning Without Centralized Data Training, Google AI Blog (Apr. 6, 2017), https://ai.googleblog.com/2017/04/ federated-learning-collaborative.html [https://perma.cc/RZ6K-MJBE]. ↑
- . See, e.g., Tony Peng, I/O 2019—Your Data Stays on Your Phone: Google Promises a Better AI, Medium Synced (May 6, 2019), https://medium.com/syncedreview/i-o-2019-your-data-stays-on-your-phone-google-promises-a-better-ai-a488971fe446 [https://perma.cc/9WDZ-MLMZ]. ↑
- . See, e.g., Zero-knowledge proof, Wikipedia, https://en.wikipedia.org/wiki/Zero-knowledge_proof, [https://perma.cc/T3TU-K9DR] (last visited Oct. 18, 2020). ↑
- . Mark Surman, Update: Digging Deeper on ‘Trustworthy AI’, Mozilla Found. (Aug. 29, 2019), https://foundation.mozilla.org/es/blog/update-digging-deeper-on-trustworthy-ai/, [https://perma.cc/9Z3U-7QT5]. ↑
- . E.g., Responsible Computer Science Challenge: Overview, Mozilla Found., https://foundation.mozilla.org/en/initiatives/responsible-cs/?source=post_page [https://perma.cc/LGF4-XW3A] (last visited Oct. 18, 2020) . ↑
- . See supra Section VI.A.3. ↑
- . See, e.g., Data Transfer Project, https://datatransferproject.dev/ [https://perma.cc/JZ68-77ZF] (last visited Oct. 18, 2020). ↑
- . See generally The Mother of All Demos, Wikipedia, https://en.wikipedia.org/wiki/The_Mother_of_All_Demos [https://perma.cc/X5W6-AN3T] (last visited Oct. 18, 2020). ↑